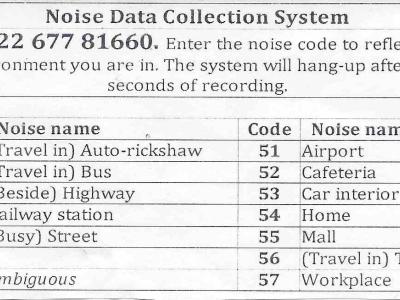
AIR-RS-DB: All India Radio Read and Spontaneous Speech Data Base

- Citation Author(s):
-
Sunil Kumar Kopparapu
 (TCS Research)
(TCS Research)
- Submitted by:
- Sunil Kumar Kopparapu
- Last updated:
- DOI:
- 10.21227/ft5v-xp41
- Data Format:
- Research Article Link:
 163 views
163 views
- Categories:
- Keywords:
Abstract
AIR-RS-DB: A dataset for classifying Spontaneous and Read Speech
A set of 1028 audio files generated from 7 mp3 files downloaded from All India Radio. https://newsonair.gov.in/ and converted into wav and then speaker diarized is using https://huggingface.co/pyannote/speaker-diarization (pyannote/speaker-diarization@2022072,model) and derive 1028 audio files.
These are available as air-rs-db.zip (which can be downloaded)
The automatic annotation of these 1028 audio files using the technique mentioned in https://arxiv.org/abs/2306.08012v1 (A Novel Scheme to classify Read and Spontaneous Speech) is recorded in air_rs_db_auto-annotation.csv (downloadable).
This file contains 4 columns separated by ":", namely, audio:dur:Readability Score:Threshold eq 1.75.
The first column is the name of the audio file. The second column is the duration of the audio file. The third column is the readability score as defined in (equation (3) in https://arxiv.org/pdf/2306.08012v1.pdf) and the fourth column is a label "R" or "S" using the threshold \tau_{cal R} = 1.75.
Note that the annotation "R" for read speach and "S" for Spontaneous speech is automatically generated.
Instructions:
How to use this database.
- Download the air-rs-db.zip from here
- There are 1028 audio files (16-bit Signed Integer PCM, sampled at 16 kHz)
- Download the auto annotation file air_rs_db_auto-annotation.csv from here
- Use cut -d":" -f1,4 air_rs_db_auto-annotation.csv to get the name of the audio file and the automatic annotation (R for read speech; S for sponatneous speech)
You can test your classifier which has the ability to distinguish read and spontaneous speech on this dataset.
A note.
- The annotations are automatic and are generated using the readability score (equation (3)) and setting a threshold of 1.75 in https://arxiv.org/abs/2306.08012v1 (A Novel Scheme to classify Read and Spontaneous Speech)
- air_rs_db_auto-annotation.csv contains 4 fields audio file name:duration of the audio :Readability Score:R/S