Machine Learning

<p>Ten individuals in good health were enlisted to execute 16 distinct movements involving the wrist and fingers in real-time. Before commencing the experimental procedure, explicit consent was obtained from each participant. Participants were informed that they had the option to withdraw from the study at any point during the experimental session. The experimental protocol adhered to the principles outlined in the Declaration of Helsinki and received approval from the local ethics committee at the National University of Sciences and Technology, Islamabad, Pakistan.
- Categories:
 136 Views
136 Views
This dataset contains MRI data acquired approximately 20 minutes before ("Pre-ablation") and 20-40 minutes after ("Post-ablation") MR-guided focused ultrasound thermal ablations in the muscle tissue (quadriceps) in four (n=4) New Zealand white rabbits. MR images include MR thermometry acquired with the proton resonance frenquency method, ADC maps (b=0,400), T2-weighted, and pre- and post-contrast enhanced T1-weighted images. All MRI acquisitions were 3D except for the ADC acquisition, which was 2D multi-slice.
- Categories:
156 Views
As communications service providers ponder ways to cater to the diverse traffic requirements of mobile applications that range from the classic telephony to modern augmented reality (AR)-related use cases, the traditional quality of service (QoS)-based radio resource management (RRM) techniques for RAN slicing that are agnostic to the intrinsic workings of applications can result in a poor quality of experience (QoE) for the end-user. We argue that in addition to QoS, RAN slicing strategies should also consider QoE for efficient resource utilization.
- Categories:
349 Views
The uploaded dataset appears to be related to various composite materials, and it includes the following columns:
- Categories:
467 Views
The published Surface Electromyography (sEMG) dataset was captured under the supervision of trained physiotherapists and doctors at Mayo Hospital Lahore and National University of Sciences & Technology by following two months long experimental protocol.
- Categories:
1156 Views
Blade damage inspection without stopping the normal operation of wind turbines has significant economic value. This study proposes an AI-based method AQUADA-Seg to segment the images of blades from complex backgrounds by fusing optical and thermal videos taken from normal operating wind turbines. The method follows an encoder-decoder architecture and uses both optical and thermal videos to overcome the challenges associated with field application.
- Categories:
1177 Views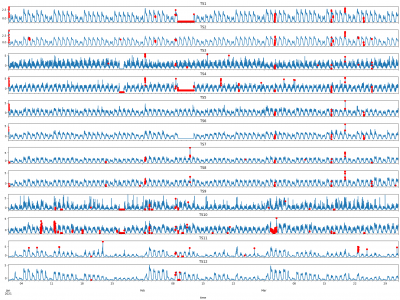
A recent study [1] alerts on the limitations of evaluating anomaly detection algorithms on popular time-series datasets such as Yahoo, Numenta, or NASA, among others. In particular, these datasets are noted to suffer from known flaws suchas trivial anomalies, unrealistic anomaly density, mislabeled ground truth, and run-to-failure bias. The TELCO dataset corresponds to twelve different time-series, with a temporal granularity of five minutes per sample, collected and manually labeled for a period of seven months between January 1 and July 31, 2021.
- Categories:
843 Views
The dataset was generated through the execution of a Python script designed to collect a comprehensive set of data samples from six different sensors for each specific gesture. Upon launching the script, users are prompted to initiate gesture 0, Once ready, users can commence recording, with the program automatically capturing 1000 samples for that particular gesture. Subsequently, the program prompts users to perform gesture 1, and this process repeats until data for all gestures is collected.
- Categories:
243 Views
The Sentinel-2 L2A multispectral data cubes include two regions of interest (roi1 and roi2) each of them containing 92 scenes across Switzerland within T32TLT, between 2018 and 2022, all band at 10m resolution These areas of interest show a diverse landscape, including regions covered by forests that have undergone changes, agriculture and urban areas.
- Categories:
1985 Views
Human biomechanics is still an active topic of research that requires more technological advancements and data collection of various human body movements. There is a need for methodologies to identify daily activities in various scenarios, such as one while carrying a school bag. Deakin university has developed an Internet of Things (IoT) enabled smart school bag consisting of motion analysis sensors that would recognize the activities performed while carrying the school bag.
- Categories:
110 Views