Machine Learning

Our large scale alpine land cover dataset consists of 229'535 very high-resolution aerial images (50cm) and digital elevation model (50cm) with land cover annotations produced by experts in photo-interpretration . The nine land cover types in our study area include bedrock, bedrock with grass, large blocks, large blocks with grass, scree, scree with grass, water area, forest and glacier. The distribution of pixels among classes presents a typical case of a long-tailed distribution with an imbalance factor, defined as the ratio of the most frequent to the rarest class, close to 1000.
- Categories:
 294 Views
294 Views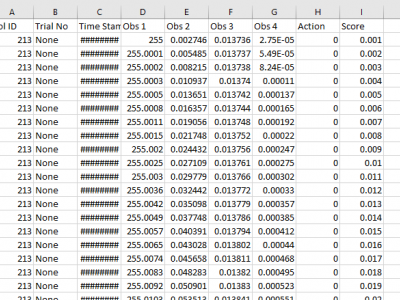
The instantaneous state (situation) of the game was constituted by four values: the cart position, the cart speed, the pole angle to the vertical axis, and the pole angular velocity.
For each action taken by the human player in the game, a tuple containing the four values representing the current game situation, along with the action and reward obtained (utility), is recorded as a situation-decision-utility (SDU) tuple.
3 types of actions have been recorded: Move left (-1), move rght (1) and no action (0).
- Categories:
34 Views
The first part of the data set contains the monthly recorded spread of covid-19 across the 6 geopolitical zones of Nigeria for the period of March 2020 to September 2022.
The second part of the data set contains the recorded covid-19 spread during religious festivals across the 6 geopolitical zones of Nigeria.
The third part contains the projected population densities of the 36 states of Nigeria alongside the number of covid-19 test centres in each state.
- Categories:
353 Views
This dataset features a wide range of synthetic American Sign Language (ASL) digits, spanning numbers 0 through 9. These ASL sign representations were meticulously crafted using Unity software, resulting in dynamic 3-D scenes set against diverse backgrounds. To enhance the dataset's comprehensiveness, it includes contributions from three distinct subjects, adding a rich variety of ASL digit gestures. This diversity makes it a valuable resource for researchers interested in ASL digit recognition and gesture analysis.
- Categories:
424 Views
This dataset is derived from a research paper proposing a wireless localization correction methodology based on Convolutional Neural Networks (CNN). The approach involves feature extraction from maps that depict both line of sight (LOS) and non-line of sight (NLOS) effects. The research includes four prediction tasks, categorizing CNN models based on building distribution and propagation mode, resulting in models with low prediction loss. Additionally, an error compensation scheme is designed using CNN-predicted localization errors.
- Categories:
191 Views
Quantifying performance of methods for tracking and mapping tissue in endoscopic environments is essential for enabling image guidance and automation of medical interventions and surgery. Datasets developed so far either use rigid environments, visible markers, or require annotators to label salient points in videos after collection. These are respectively: not general, visible to algorithms, or costly and error-prone. We introduce a novel labeling methodology along with a dataset that uses said methodology, Surgical Tattoos in Infrared (STIR).
- Categories:
2443 Views
Internet-of-Things (IoT) technology such as Surveillance cameras are becoming a widespread feature of citizens' life. At the same time, the fear of crime in public spaces (e.g., terrorism) is ever-present and increasing but currently only a small number of studies researched automatic recognition of criminal incidents featuring artificial intelligence (AI), e.g., based on deep learning and computer vision. This is due to the fact that little to none real data is available due to legal and privacy regulations. Consequently, it is not possible to train and test deep learning models.
- Categories:
746 Views
This LTE_RFFI project sets up an LTE device radio frequency fingerprint identification system using deep learning techniques. The LTE uplink signals are collected from ten different LTE devices using a USRP N210 in different locations. The sampling rate of the USRP is 25 MHz. The received signal is resampled to 30.72 MHz in Matlab. Then, the signals are processed and saved in the MAT file form. More details about the datasets can be found in the README document.
- Categories:
1029 Views
Mapping millions of buried landmines rapidly and removing them cost-effectively is supremely important to avoid their potential risks and ease this labour-intensive task. Deploying uninhabited vehicles equipped with multiple remote sensing modalities seems to be an ideal option for performing this task in a non-invasive fashion. This report provides researchers with vision-based remote sensing imagery datasets obtained from a real landmine field in Croatia that incorporated an autonomous uninhabited aerial vehicle (UAV), the so-called LMUAV.
- Categories:
1380 Views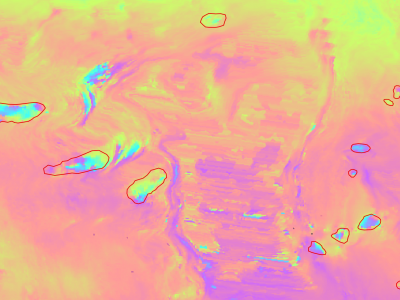
Slow moving motions are mostly tackled by using the phase information of Synthetic Aperture Radar (SAR) images through Interferometric SAR (InSAR) approaches based on machine and deep learning. Nevertheless, to the best of our knowledge, there is no dataset adapted to machine learning approaches and targeting slow ground motion detections. With this dataset, we propose a new InSAR dataset for Slow SLIding areas DEtections (ISSLIDE) with machine learning. The dataset is composed of standardly processed interferograms and manual annotations created following geomorphologist strategies.
- Categories:
1266 Views