Image Processing

Table1 present the peak-level activation point of 8 brain regions for all 1080 subjects.
Table2 present the peak-level activation point of 8 brain regions for selected 893 subjects.
Supplementary data -RotL.rar present the SPM{T}map and extracted masks calculated with 2nd-level modeling analysis from RtoL fMRI data of subjects 1 to 50.
Supplementary data -LtoR.rar present the SPM{T}map and extracted masks calculated with 2nd-level modeling analysis from LtoR fMRI data of subjects 1 to 50.
- Categories:
 167 Views
167 Views
A paradigm dataset is constantly required for any characterization framework. As far as we could possibly know, no paradigmdataset exists for manually written characters of Telugu Aksharaalu content in open space until now. Telugu content (Telugu: తెలుగు లిపి, romanized: Telugu lipi), an abugida from the Brahmic group of contents, is utilized to compose the Telugu language, a Dravidian language spoken in the India of Andhra Pradesh and Telangana just a few other neighboring states. The Telugu content is generally utilized for composing Sanskrit writings.
- Categories:
16925 Views
A benchmark dataset is always required for any classification or recognition system. To the best of our knowledge, no benchmark dataset exists for handwritten character recognition of Manipuri Meetei-Mayek script in public domain so far. Manipuri, also referred to as Meeteilon or sometimes Meiteilon, is a Sino-Tibetan language and also one of the Eight Scheduled languages of Indian Constitution. It is the official language and lingua franca of the southeastern Himalayan state of Manipur, in northeastern India.
- Categories:
1206 Views
Multi-modal Exercises Dataset is a multi- sensor, multi-modal dataset, implemented to benchmark Human Activity Recognition(HAR) and Multi-modal Fusion algorithms. Collection of this dataset was inspired by the need for recognising and evaluating quality of exercise performance to support patients with Musculoskeletal Disorders(MSD).The MEx Dataset contains data from 25 people recorded with four sensors, 2 accelerometers, a pressure mat and a depth camera.
- Categories:
1687 Views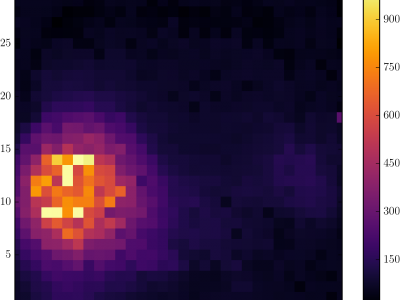
This data set comprises 4223 videos from a laser surface heat treatment process (also called laser heat treatment) applied to cylindrical workpieces made of steel. The purpose of the dataset is to detect anomalies in the laser heat treatment learning a model from a set of non-anomalous videos.
In the laser heat treatment, the laser beam is following a pattern similar to an "eight" with a frequency of 100 Hz. This pattern is sometimes modified to avoid obstacles in the workpieces.
- Categories:
682 Views
Hyperspectral (HS) imaging presents itself as a non-contact, non-ionizing and non-invasive technique, proven to be suitable for medical diagnosis. However, the volume of information contained in these images makes difficult providing the surgeon with information about the boundaries in real-time. To that end, High-Performance-Computing (HPC) platforms become necessary. This paper presents a comparison between the performances provided by five different HPC platforms while processing a spatial-spectral approach to classify HS images, assessing their main benefits and drawbacks.
- Categories:
1589 Views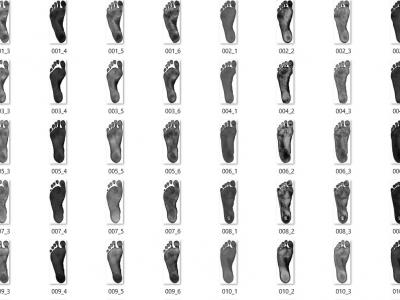
Present dataset intended to give human footprint a legal capacity. The human footprint can be a good candidate for biometric identification. The presented dataset has been created using EPSON 5500 Scanner, which is an ordinary PSC machine. This dataset consists of 6 right side multispectral footprints per person from 220 volunteers captured at different periods.
- Categories:
1767 Views
Drive testing is a common practice by mobile operators to evaluate the performance and coverage of their deployed mobile communication systems. Drive testing is, however, a very expensive practice. Furthermore, due to the complexity of future 5G mobile networks, accurate and efficient ways of optimizing and evaluating coverage are needed. The dataset contains measurements from a deployed LTE-A mobile communication system and corresponding satellite images.
- Categories:
4245 Views
Starfish color image from Berkely dataset.
- Categories:
428 Views
We collect almost 248,166 public microblogs according to selected 97 hashtags of "Top 100" on Instagram. The final collection contains 56861 microblogs which include both text and image, called MultiModal data from Instagram (MM-INS). We filter duplicate hashtags in one sample and drop out those microblogs without texts.
- Categories:
1517 Views