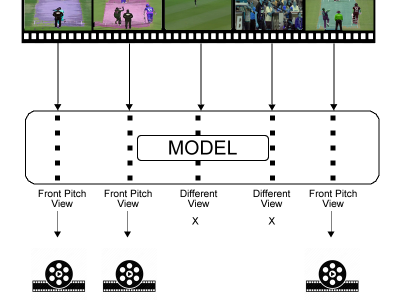
Directed Acyclic Graph (DAG) blockchain applications represent an evolution from traditional linear blockchain solutions, addressing their inherent scalability issues. The analysis of the transactions fee market in these applications proves particularly insightful, given their demonstrated ability to manage very high transaction throughputs, and the crucial role transaction fees play in blockchain sustainability, efficiency and security, as a mechanism to incentivize validators and regulate network congestion.
- Categories: