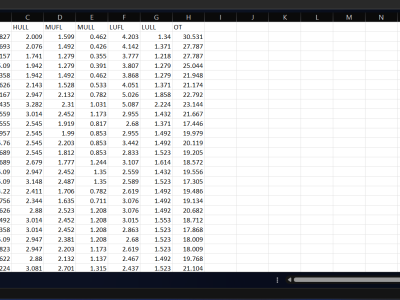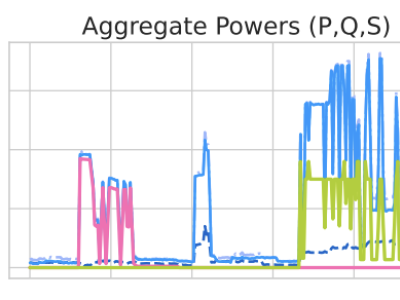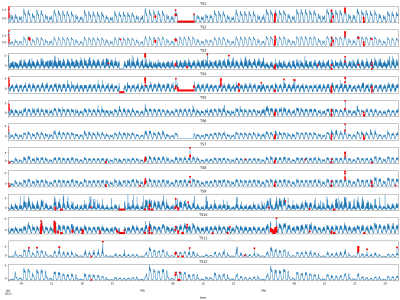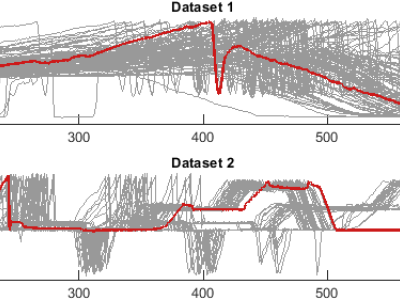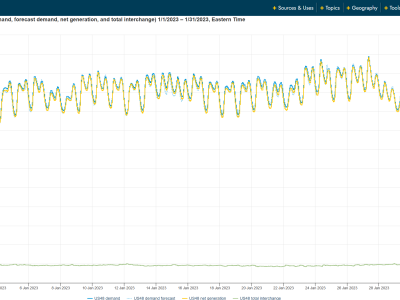
This dataset contains hourly electricity demand data and corresponding weather indicators collected from 2021 to 2023. The electricity data was sourced from the U.S. Energy Information Administration (EIA), covering both winter and summer periods across three years. Weather features—including temperature, wind speed, and humidity—were collected to capture the external conditions affecting demand. All files are stored in CSV format and aligned by timestamp. This dataset supports research in time series forecasting, demand prediction, and energy systems modeling.
- Categories: