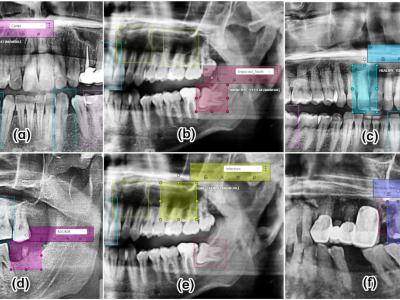
- Categories:

This dataset contains both the artificial and real flower images of bramble flowers. The real images were taken with a realsense D435 camera inside the West Virginia University greenhouse. All the flowers are annotated in YOLO format with bounding box and class name. The trained weights after training also have been provided. They can be used with the python script provided to detect the bramble flowers. Also the classifier can classify whether the flowers center is visible or hidden which will be helpful in precision pollination projects.

This dataset is derived from Sentinel-2 satellite imagery.
The main goal is to employ this dataset to train and classify images into two classes: with trees, and without trees.
The structure of the dataset is 2 folders named: "tree" (images containing trees) and "no-trees" (images without presence of trees).
Each folder contains 5200 images of this type.

Lettuce Farm SLAM Dataset (LFSD) is a VSLAM dataset based on RGB and depth images captured by VegeBot robot in a lettuce farm. The dataset consists of RGB and depth images, IMU, and RTK-GPS sensor data. Detection and tracking of lettuce plants on images are annotated with the standard Multiple Object Tracking (MOT) format. It aims to accelerate the development of algorithms for localization and mapping in the agricultural field, and crop detection and tracking.
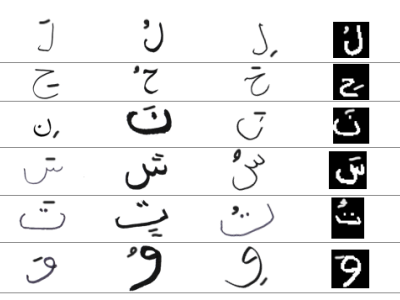
AHT2D dataset is composed of Handwritten Arabic letters with diacritics. In this dataset, we have 28 letter classes according to the number of Arabic letters. Each class contains a multiple letter form. We have different letter images from different sources such as the internet, our writers, etc. The AHT2D dataset includes only isolated letters. In addition, this dataset contains different writing styles, orientations, colors, thicknesses, sizes, and backgrounds, which makes it a very large and rich dataset.
Accurate detection and segmentation of apple trees are crucial in high throughput phenotyping, further guiding apple trees yield or quality management. A LiDAR and a camera were attached to the UAV to acquire RGB information and coordinate information of a whole orchard. The information was integrated by simultaneous localization and mapping network to form a dataset of RGB-colored point clouds. The dataset can be used for methods related to apple detection and segmentation based on point clouds.
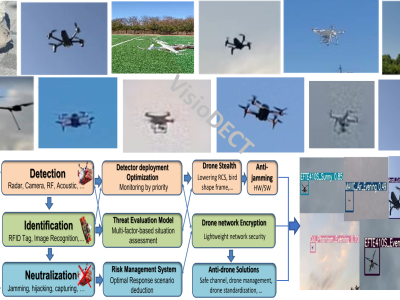
The deployment of unmanned aerial vehicles (UAV) for logistics and other civil purposes is consistently disrupting airspace security. Consequently, there is a scarcity of robust datasets for the development of real-time systems that can checkmate the incessant deployment of UAVs in carrying out criminal or terrorist activities. VisioDECT is a robust vision-based drone dataset for classifying, detecting, and countering unauthorized drone deployment using visual and electro-optical infra-red detection technologies.

This dataset is a collection of images and their respective labels containing multiple Indian coins of different denominations and their variations. The dataset only contains images of one side of each coin (Tail side) which contains the denomination value.
The samples were collected with the help of a mobile phone while the coins were placed on top of a white sheet of A4-sized paper.
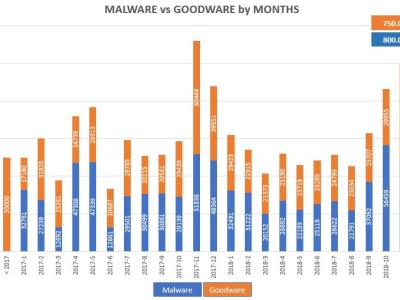
This dataset is part of my Master's research on malware detection and classification using the XGBoost library on Nvidia GPU. The dataset is a collection of 1.55 million of 1000 API import features extract from jsonl format of the EMBER dataset 2017 v2 and 2018. All data is pre-processing, duplicated records are removed. The dataset contains 800,000 malware and 750,000 "goodware" samples.

The dataset comprises of image file s of size 20 x 20 pixels for various types of metals and non-metal.The data collected has been augmented, scaled and modified to represent a number a training set dataset.It can be used to detect and identify object type based on material type in the image.In this process both training data set and test data set can be generated from these image files.