AHT2D dataset
- Citation Author(s):
-
Imene OUALI
 (REGIM-Lab)
Mohamed BEN HALIMA (REGIM-Lab)Ali WALI (REGIM-Lab)
(REGIM-Lab)
Mohamed BEN HALIMA (REGIM-Lab)Ali WALI (REGIM-Lab) - Submitted by:
- Imene OUALI
- Last updated:
- DOI:
- 10.21227/t7t3-5k24
- Data Format:
- Research Article Link:
 835 views
835 views
- Categories:
- Keywords:
Abstract
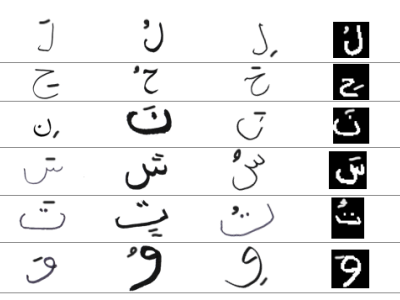
AHT2D dataset is composed of Handwritten Arabic letters with diacritics. In this dataset, we have 28 letter classes according to the number of Arabic letters. Each class contains a multiple letter form. We have different letter images from different sources such as the internet, our writers, etc. The AHT2D dataset includes only isolated letters. In addition, this dataset contains different writing styles, orientations, colors, thicknesses, sizes, and backgrounds, which makes it a very large and rich dataset. AHT2D is composed of three different files, which not only facilitates the tasks of text detection and recognition but also enable good results. These three files are training, testing, and validation. In our proposed model, we first divide our dataset into three sets: the training set, the test set, and the validation set. The split of our dataset is as follows. The training set has 80\% of the total dataset images. The rest is divided into testing and validation. The test set contains 80\% of the remaining images. Furthermore, the validation set contains 20\%. Finally, the processing step enhances and augments the images, as well as the data.
Instructions:
AHT2D dataset.
This database can help researchers to evaluate their work by running their models on this database to have the accuracy of their Arabic text detection and recognition method.






