Machine Learning

Classifying the driving styles is of particular interest for enhancing road safety in smart cities. The vehicle can assist the driver by providing advice to increase awareness of potential dangers. Accordingly, dissuasive measures, such as adjusting insurance costs, can be implemented. The service is called Pay-As-You-Drive insurance (PAYD), and to address it, the paper introduces a method for constructing a database of simulated driver behaviors using the Simulation of Urban MObility Simulation of Urban MObility (SUMO) simulator.
- Categories:
 372 Views
372 Views
This dataset consists of 462 field of views of Giemsa(dye)-stained and field(dye)-stained thin blood smear images acquired using an iPhone 10 mobile phone with a 12MP camera. The phone was attached to an Olympus microscope with 1000× objective lens. Half of the acquired images are red blood cells with a normal morphology and the other half have a Rouleaux formation morphology.
- Categories:
1018 Views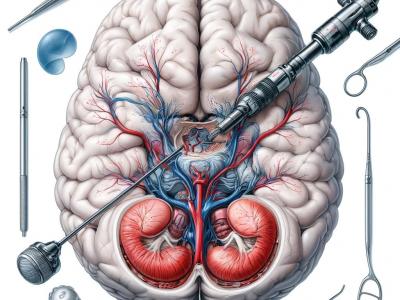
This dataset comprises 1718 annotated images extracted from 29 video clips recorded during Endoscopic Third Ventriculostomy (ETV) procedures, each captured at a frame rate of 25 FPS. Out of these images, 1645 are allocated for the training set, while the remainder is designated for the testing set. The images contain a total of 4013 anatomical or intracranial structures, annotated with bounding boxes and class names for each structure. Additionally, there are at least three language descriptions of varying technicality levels provided for each structure.
- Categories:
422 Views
This data reflects the prevalence and adoption of smart devices. The experimental setup to generate the IDSIoT2024 dataset is based on an IoT network configuration consisting of seven smart devices, each contributing to a diverse representation of IoT devices. These include a smartwatch, smartphone, surveillance camera, smart vacuum and mop robot, laptop, smart TV, and smart light. Among these, the laptop serves a dual purpose within the network.
- Categories:
1837 Views
¢This study delves into the connections between green ELT, DEIB, virtual reality, mediation, life skills, and task-based teaching, learning, and assessment in the context of sustainable and inclusive education. The study emphasizes the significance of incorporating ecological concepts into language instruction, advocating for diversity, fairness, and inclusivity in learning environments, and using virtual reality technology to augment language acquisition.
- Categories:
165 Views
Human facial data hold tremendous potential to address a variety of classification problems, including face recognition, age estimation, gender identification, emotion analysis, and race classification. However, recent privacy regulations, such as the EU General Data Protection Regulation, have restricted the ways in which human images may be collected and used for research.
- Categories:
399 Views
The dataset provides an end-to-end (E2E) perspective of the performance of 360-video services over mobile networks. The data was collected using a network-in-a-box setup in conjunction with a Meta Quest 2 head-mounted display (HMD) and a customer premises equipment (CPE) to provide 5G connectivity to the glasses (WiFi-native).
- Categories:
183 Views
The development of metaverses and virtual worlds on various platforms, including mobile devices, has led to the growth of applications in virtual reality (VR) and augmented reality (AR) in recent years. This application growth is paralleled by a growth of interest in analyzing and understanding AR/VR applications from security and performance standpoints. Despite this growing interest, benchmark datasets are lacking to facilitate this research pursuit.
- Categories:
499 Views
This is the pest image dataset. With this data set at hand, scientists or software engineers may create programs capable of recognizing when creatures harm farm produce. This breadth extends not only across different plants but also covers many types of bugs like aphids, leafhoppers, beetles , caterpillars etcetera providing a large diverse pool from which one can train models designed to detect pests. Arranging photos by pest species makes it easy for people looking into them understand what they should expect find.
- Categories:
2154 Views
The original data includes structured and unstructured impact factors. The structured impact factors are from the wind database, and the unstructured impact factors are from the official Baidu Index website, obtained through the Python 3.8 crawler.
The preprocessed data is filled with the original data after excluding outliers and some missing values, which is used to screen influencing factors.
- Categories:
152 Views