Machine Learning

The terahertz communications band in the 252 to325 GHz range has been recently explored for its potential to meet the stringent requirements for the emerging sixth generation of wireless communications. However, there are several challenges including noise and nonlinearity that hinder efficient implementations. We aim to address this limitation in terahertz communications through convolutional neural networks (CNN) enhanced by the domain knowledge from traditional Volterra filters.
- Categories:
 287 Views
287 Views
We evaluate the performance of our proposed protocol using three benchmark datasets. Each dataset is composed of 25 percent of the local data forming the test dataset and 75 percent of the local data forming the training dataset.
MNIST: The dataset is made up of gray pictures that are digits which are written by hand containing ten different classes which provides 60000 training samples in total.
- Categories:
128 Views
The dataset contains 560 different observations each having 1049 absorption data points for cancerous and non-cancerous skin cells. The reflection absorption data were obtained from terahertz metamaterials on top of which the cells are placed. The 560 observations made were for varying size tissue thickness and polarization and incident wave angle
- Categories:
416 Views
The dataset contains Game stats for all matches in the League of Legends LEC Spring Playoffs 2024. It has 81 columns and 420 rows. Here is the description of the columns.
Dataset Contents:
● Player: Name of the player.
● Role: Role of the player (e.g., TOP, JUNGLE, MID, ADC, SUPPORT)
● Team: Name of the player's team
● Opponent_Team: Name of the opposing team
- Categories:
405 Views
We introduce two novel datasets for cell motility and wound healing research: the Wound Healing Assay Dataset (WHAD) and the Cell Adhesion and Motility Assay Dataset (CAMAD). WHAD comprises time-lapse phase-contrast images of wound healing assays using genetically modified MCF10A and MCF7 cells, while CAMAD includes MDA-MB-231 and RAW264.7 cells cultured on various substrates. These datasets offer diverse experimental conditions, comprehensive annotations, and high-quality imaging data, addressing gaps in existing resources.
- Categories:
966 Views
Moroccan Dialect Emotion Recognition Dataset is a collection of voice records of people speaking Moroccan dialect in 5 states of emotion: Neutral, Happy, Sad, Angry and Fearful. The dataset has been collected in different Moroccan cities in 2024. Each recorder has 5 records per emotion class. The dataset contains 2000 record. The records are saved in .wav format, which is useful for signal processing with python libraries. The dataset is used for signal processing and emotion recognition using deep Learning models.
- Categories:
521 Views
Anomaly detection in Phasor Measurement Unit (PMU) data requires high-quality, realistic labeled datasets for algorithm training and validation. Obtaining real field labelled data is challenging due to privacy, security concerns, and the rarity of certain anomalies, making a robust testbed indispensable. This paper presents the development and implementation of a Hardware-in-the-Loop (HIL) Synchrophasor Testbed designed for realistic data generation for testing and validating PMU anomaly detection algorithms.
- Categories:
1480 Views
Advancements in Medical Vision-Language Pre-training (Medical-VLP) progress rapidly by learning representations from paired radiology reports. Nevertheless, there still remain two issues that restrict the development of Medical-VLP: the scarcity of parallel image-report pair and monotony of pre-training tasks. Thus, we propose Multi-Grained Cross-Domain Report Searching (CDRS) strategy, and Multi-Task Driven Language-Image Pre-Training (MLIP) framework.
- Categories:
72 Views
The detection of the collapse of landslides trigerred by intense natural hazards, such as earthquakes and rainfall, allows rapid response to hazards which turned into disasters. The use of remote sensing imagery is mostly considered to cover wide areas and assess even more rapidly the threats. Yet, since optical images are sensitive to cloud coverage, their use is limited in case of emergency response. The proposed dataset is thus multimodal and targets the early detection of landslides following the disastrous earthquake which occurred in Haiti in 2021.
- Categories:
1014 Views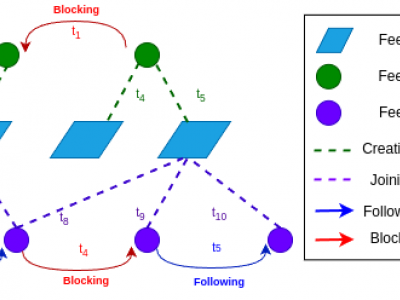
Decentralized social media platforms like Bluesky Social (Bluesky) have made it possible to publicly disclose some user behaviors with millisecond-level precision. Embracing Bluesky's principles of open-source and open-data, we present the first collection of the temporal dynamics of user-driven social interactions. BlueTempNet integrates multiple types of networks into a single multi-network, including user-to-user interactions (following and blocking users) and user-to-community interactions (creating and joining communities).
- Categories:
1203 Views