Machine Learning

Any work using this dataset should cite the following paper:
- Categories:
 1878 Views
1878 Views
- Categories:
1738 Views
- Categories:
2123 Views
- Categories:
Views
These simulated live cell microscopy sequences were generated by the CytoPacq web service https://cbia.fi.muni.cz/simulator [R1]. The dataset is composed of 51 2D sequences and 41 3D sequences. The 2D sequences are divided into distinct 44 training and 7 test sets. The 3D sequences are divided into distinct 34 training and 7 test sets. Each sequence contains up to 200 frames.
- Categories:
313 Views
The dataset represents the negative interaction dataset of the Drugbank that has been generated from our proposed machine learning method based on drug similarity, which achieved an average accuracy of 95% compared to the randomly generated negative datasets in the literature. Drugbank was used as the drug target interaction dataset from https://go.drugbank.com/.
- Categories:
1063 Views
This dataset contains measurements of TPC-C benchmark executions in MySQL server deployed in Google Cloud Platform.
- Categories:
343 Views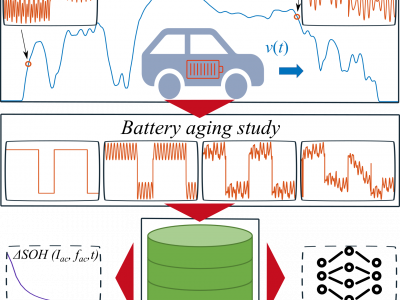
The SiCWell Dataset contains data of battery electric vehicle lithium-ion batteries for modeling and diagnosis purposes. In this experiment, automotive-grade lithium-ion pouch bag cells are cycled with current profiles plausible for electric vehicles.
The analysis of current ripples in electric vehicles and the corresponding aging experiments of the battery cells result in a dataset, which is composed of the following parts:
- Categories:
6397 Views
This dataset contains world news related to politics and also with the news article's available metadata.
- Categories:
1155 Views
This dataset contains world news related to Science and technology and also with the news article's available metadata.
- Categories:
785 Views