Machine Learning
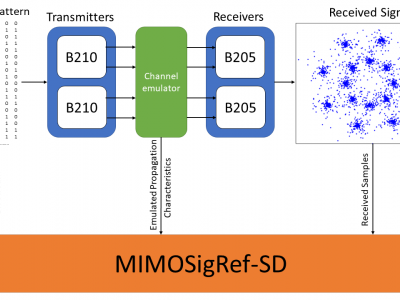
The MIMOSigRef-SD dataset was created with the goal to support the research community in the design and development of novel multiple-input multiple-ouotput (MIMO) transceiver architectures. It was recorded using software radios as transmitters and receivers, and a wireless channel emulator to facilitate a realistic representation of a variety of different channel environments and conditions.
- Categories:
 1984 Views
1984 Views
Protein molecules are inherently dynamic and modulate their interactions with different molecular partners by accessing different tertiary structures under physiological conditions.Elucidating such structures remains challenging. Current momentum in deep learning and the powerful performance of generative adversarial networks (GANs) in complex domains, such as computer vision, inspires us to investigate GANs on their ability to generate physically-realistic protein tertiary structures.
- Categories:
688 Views
The dataset is generated by performing different MiTM attacks in the synthetic electric grid in RESLab testbed at Texas A&M University, US. The testbed primarily consists of a dynamic power system simulator (Powerworld Dynamic Studio), network emulator (CORE), Snort IDS, open DNP3 master and Elasticsearch's Packetbeat index. There are raw and processed files that can be used by security enthusiasts to develop new features and also to train IDS using our feature space respectively.
- Categories:
3080 Views
This dataset is for short-term spatio-temporal PV forecasting.
This dataset consists of three two parts. The first part is the spatio-temporal PV dataset which obatined from different PV sites. The second part is the corresponding weather datasets, including temperature, wind speed, wind direction, etc.
The dataset also contains the demo codes for showing the concept of a machine learning based PV forecasting model.
More information will be added in the future.
- Categories:
837 Views
The dataset is part of the MIMIC database and specifically utilise the data corresponding to two patients with ids 221 and 230.
- Categories:
1009 Views
This data set is the result of model test trained on the basis of the Stanford earthquake dataset (stead): a global data set of seismic signals for AI, which can effectively get the seismic signal and the arrival time of seismic phase from the image, so as to prove the effectiveness of this model
- Categories:
582 Views
Online Machine Learning for Energy-Aware Multicore Real-Time Embedded Systems Dataset is a Dataset composed of Hardware Performance Counters extracted from a Multicore Real-Time Embedded System. This Dataset encompasses every Monitorable Performance counters in a Cortex-A53 quad-core processor, totaling 54 performance counters, which are sampled periodically through a non-Intrusive Monitoring Framework implemented over Embedded Parallel Operating System (EPOS), a Real-Time Operating System.
- Categories:
402 Views
The dataset consists of the ISFET sensor data utilized to train ML models for drift compensation.
- Categories:
465 Views
The current dataset – crowdbot – presents outdoor pedestrian tracking from onboard sensors on a personal mobility robot navigating in crowds. The robot Qolo, a personal mobility vehicle for people with lower-body impairments was equipped with a reactive navigation control operating in shared-control or autonomous mode when navigating on three different streets of the city of Lausanne, Switzerland during farmer’s market days and Christmas market. Full Dataset here: DOI:10.21227/ak77-d722
- Categories:
2604 Views
India is known for its highly disciplined foreign policies, strategic location, vibrant and massive Diaspora. India envisages enhancing its scope of cooperation, trade and widens its sphere of relations with the Pacific. As a result, the world is witnessing the rise of Indo-Pacific ties. Before the 1980’s the keystone of the universe was called the Atlantic, but now a radical shift to the east is noticed by the term “Indo-Pacific‟.
- Categories:
626 Views