Cloud Computing

We utilized Digital Ocean's cloud service, setting up three Linux virtual machines, each with 1vCPU, 1GB of memory, and a 10GB disk. The architecture included an API gateway for routing requests to a stateless application service backed by a database for storing application data. The application operates the service under a fluctuating workload generated by a load-testing script to simulate real-world usage scenarios. The target source or the application service is integrated with Prometheus, a monitoring tool for gathering system metrics.
- Categories:
 549 Views
549 Views
The Reflection Server Tuning dataset contains HiPerConTracer latency measurements performed in a lab setup. The purpose of the dataset is to measure the latency and jitter effects of firewalls and Linux kernel tuning.
- Categories:
259 Views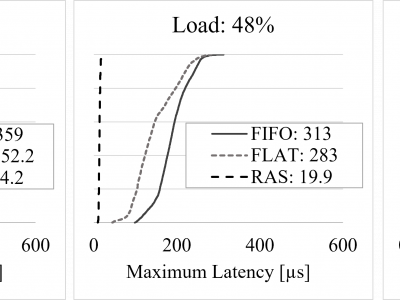
The data set was used to produce three figures (Figs. 4, 5, and 6) in the experimental section of a manuscript submitted for review to the IEEE Communications Magazine. The submission, titled Lightweight Determinism in Large-Scale Networks, describes a novel approach to the realization of network determinism in packet-switched networks of generic size and topology.
- Categories:
403 Views
The advent of the Internet of Things has increased the interest in automating mission-critical processes from domains such as smart cities. These applications' stringent Quality of Service (QoS) requirements motivate their deployment through the Cloud-IoT Continuum, which requires solving the NP-hard problem of placing the application's services onto the infrastructure's devices. Moreover, as the infrastructure and application change over time, the placement needs to continuously adapt to these changes to maintain an acceptable QoS.
- Categories:
201 Views
The Transport-level pAcket RouTing ANalysis Tool for Cloud-native Applications (TARTAN) Dataset contains TARTAN/HiPerConTracer Traceroute runs between an endpoint in Oslo, Norway and the public Comprehensive TeX Archive Network (CTAN, https://www.ctan.org) and Comprehensive R Archive Network (CRAN, https://cran.r-project.org) mirror we
- Categories:
412 Views
When designing task scheduling algorithms in mobile edge computing (MEC), the mobile device (MD)'s mobility becomes an important concern, since the change in MD's location would affect the data transmission rate, leading to fluctuations in task transmission duration and completion time. In this paper, we study a mobility-aware task off-and-downloading scheduling problem in MEC, considering both the communication delay and energy consumption caused by the data offloading and the result downloading.
- Categories:
936 Views
This quantitative correlational research study aimed to investigate the factors affecting the implementation of zero-trust security and multifactor authentication (MFA) in a fog computing environment. Fog computing is an emerging decentralized technology that extends cloud computing capabilities near the user. A fog computing environment helps in faster communication with the internet of things (IoT) devices and reduces data transmission overheads.
- Categories:
593 Views
Predicting the data transfer throughput of cloud networks plays an important role in several resource optimization applications, such as auto-scaling, replica selection, and load balancing. However, constant short-term variations in cloud networks make the prediction of end-to-end data transfer throughput a very challenging task.
- Categories:
338 Views
This data collection focuses on capturing user-generated content from the popular social network Reddit during the year 2023. This dataset comprises 29 user-friendly CSV files collected from Reddit, containing textual data associated with various emotions and related concepts.
- Categories:
2162 Views
Goal
The goal of this project is to leverage Amazon Web Service's machine learning services to create a dataset that automatically adds and updates files on IEEE DataPort's S3 storage. Through this process, we sought to learn and demonstrate how an ongoing data collection script can create a shared living dataset by streaming data to our IEEE DataPort dataset storage. In the process, we also hoped to gain further insights into areas including:
- Categories:
244 Views