Cloud Computing

The softwarization and virtualization of the fifth-generation (5G) cellular networks bring about increased flexibility and faster deployment of new services. However, these advancements also introduce new vulnerabilities and unprecedented attack surfaces. The cloud-native nature of 5G networks mandates detecting and protecting against threats and intrusions in the cloud systems.
- Categories:
 344 Views
344 Views
This dataset contains CoreMark result on azure Virtual machines in west Europe and Poland central regions. The dataset covers all available virtual machine types in given region form 2 CPU up to 20 CPU's. The dataset consists of VM type, actual processor that was running the CoreMark workload, number of iterations per second, total ticks, length of test is seconds, compiler version of the Microsoft Azure region that was chosen for the test. The dataset has 4772 row which is equal to the number of experiments run on each Virtual machine.
- Categories:
131 Views
Alibaba Cluster Trace (cluster-trace-v2018) . The dataset comprises metadata and runtime information concern-ing 4K machines, 71K online services, and 4M batch jobs over an 8-day horizon. Compared with the cluster-trace-v2017 dataset, this dataset features a longer sampling period, a larger number of workloads, and more fine-grained directed acyclic graph (DAG) dependency information.
- Categories:
364 Views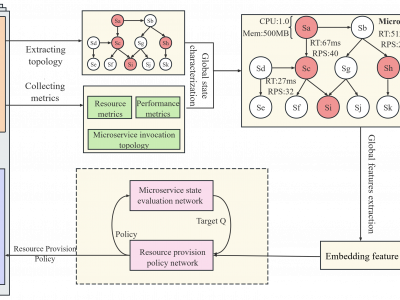
This dataset contains the source data and experimental result data required by the tarp project. The cover depicts our proposed adaptive resource allocation approach based on graph neural networks for optimizing qos-aware interactive microservices in cloud computing. This method uses DAG topology to extract the global characteristics of microservices, and adaptively generates microservice resource allocation strategies, which can effectively use microservice resources while ensuring the quality of service.
- Categories:
153 Views
This dataset is composed of 2000 time-series (1000 Read and 1000 Write) realized from the much larger cloud storage workload released to the research community by the Alibaba group. The original dataset can be download from here: (https://github.com/alibaba/block-traces).
This original dataset collected over 31 days contains read/write data for 1000 storage volumes. The schema for each file given the file names and columns per file is explained:
- Categories:
474 Views
This dataset plays a pivotal role in facilitating efficient resource management strategies, catering to the complex needs of modern Fog/Cloud environments. It comprises comprehensive information regarding machine configurations, task requirements, and bandwidth allotments. These details are indispensable for optimizing resource utilization, ensuring tasks are assigned to suitable machines based on their capabilities, and managing bandwidth allocation to prevent bottlenecks and maximize network efficiency.
- Categories:
475 Views
These datasets are collected from the tests that were performed for decentralized synchronization among collaborative robots via 5G and Ethernet networks using with/without causal message ordering. These files have different names depending on the connection type and causality type. For example, 5G_with_causality.txt file stores the test results which were performed on a public 5G network using causal message ordering for different cobot groups like 5,10,20,30,40. The test results for each robot group are separated in each txt file.
- Categories:
29 Views
Containerization has emerged as a revolutionary technology in the software development and deployment industry. Containers offer a portable and lightweight solution that allows for packaging applications and their dependencies systematically and efficiently. In addition, containers offer faster deployment and near-native performance with isolation and security drawbacks compared to Virtual Machines. To address the security issues, scanning tools that scan containers for preexisting vulnerabilities have been developed, but they suffer from false positives.
- Categories:
91 Views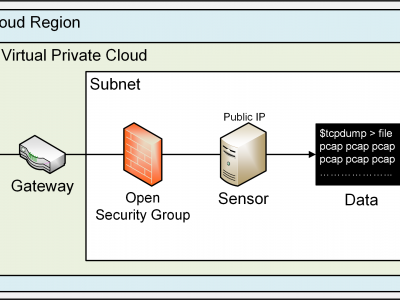
This dataset results from a 47-day Cloud Telescope Internet Background Radiation collection experiment conducted during the months of August and September 2023. A total amount of 260 EC2 instances (sensors) were deployed across all the 26 commercially available AWS regions at the time, 10 sensors per region. A Cloud Telescope sensor does not serve information. All traffic arriving to the sensor is unsolicited, and potentially malicious. Sensors were configured to allow all unsolicited traffic.
- Categories:
546 Views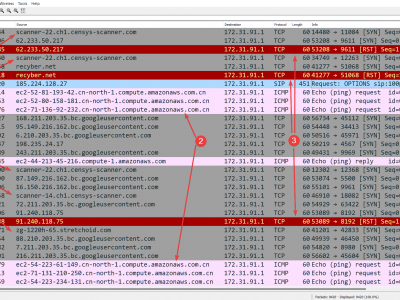
This dataset results from a month-long cloud-based Internet Background Radiation observation conducted in May 2023.
A sensor fleet comprised of 26 EC2 compute instances was deployed within Amazon Web Services across their 26 commercially available regions, 1 sensor per region.
The dataset contains 21,856,713 incoming packets, out of which 17,008,753 are TCP datagrams, 3,076,855 are ICMP packets and the remainder, 1,770,418 are UDP messages.
- Categories:
595 Views