Artificial Intelligence

The data set has been prepared as 2 different versions. The data set was shared in two versions due to the fact that the researchers could easily reproduce the tests and hardware limitations. The first version (small_dataset) was prepared using a 10% sub-sample of all dataset. The other version (big_dataset) contains the entire data. In this study, the scenarios tested were run on the small_dataset. The most successful configuration that was selected as a result of the analysis on small_dataset was applied to big_dataset.
- Categories:
 668 Views
668 Views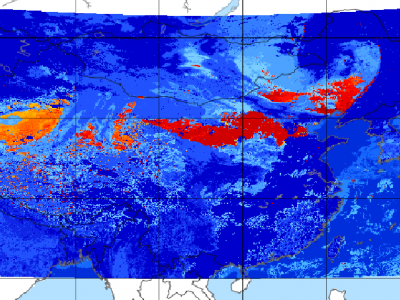
Since meteorological satellites can observe the Earth’s atmosphere from a spatial perspective at a large scale, in this paper, a dust storm database is constructed using multi-channel and dust label data from the Fengyun-4A (FY-4A) geosynchronous orbiting satellite, namely, the Large-Scale Dust Storm database based on Satellite Images and Meteorological Reanalysis data (LSDSSIMR), with a temporal resolution of 15 minutes and a spatial resolution of 4 km from March to May of each year during 2020–2022.
- Categories:
749 Views
We collected relevant data of ultrasonic Doppler flowmeter in the laboratory to study the error of ultrasonic Doppler flowmeter. It contains four sets of data at different turbidities and four sets of data at different liquid levels. Each set of data under different turbidities contains 440 pieces of data, and each set of experiments under different liquid levels contains 220 pieces of data. The entire data set has a total of 2720 pieces of data. The training set test split is 8:2, which we have already split in the uploaded data set.
- Categories:
68 Views
Acute myocardial infarction (AMI) is the main cause of death in developed and developing countries. AMI is a serious medical problem that necessitates hospitalization and sometimes results in death. Patients hospitalized in the emergency department (ED) should therefore receive an immediate diagnosis and treatment. Many studies have been conducted on the prognosis of AMI with hemogram parameters. However, no study has investigated potential hemogram parameters for the diagnosis of AMI using an interpretable artificial intelligence-based clinical approach.
- Categories:
1236 Views
Using this data, we conduct an extensive investigation into the phenomenon of homophily in the generation of hate speech on Twitter, shedding light on an essential aspect of understanding online hate speech dynamics. We introduce innovative methods to detect multiple forms of hate speech, including manifestations of racism and sexism. Furthermore, we propose and validate novel measures for quantifying familiarity and similarity on Twitter, providing a comprehensive framework for understanding the interactions among users.
- Categories:
85 Views
The "Multi-modal Sentiment Analysis Dataset for Urdu Language Opinion Videos" is a valuable resource aimed at advancing research in sentiment analysis, natural language processing, and multimedia content understanding. This dataset is specifically curated to cater to the unique context of Urdu language opinion videos, a dynamic and influential content category in the digital landscape.
Dataset Description:
- Categories:
281 Views
This data set contains:
- Training dataset: 271 CT-scans of inner ears used for optimization and training of the model.
- Validation dataset: 70 CT-scans of inner ears used for external validation.
- Categories:
381 Views
SSADLog is a novel log-based anomaly detection framework. It introduces a hyper-efficient log data pre-processing method that generates a representative subset of small sample logs. This is SSADLog pre-processed BGL dataset which are used in training, test1 and test2. You can see the small sample datasets significantly reduce the time required to execute the entire SSADLog framework but still provide a holistic understanding of the original log sequences.
- Categories:
165 Views
Data on 2355 COVID-19 cases by date of July to December 2021 were extracted from a data set recorded by COVID-19 referral centers at Qazvin province in Iran. We recorded a wide range of clinical characteristics including age, sex, previous diseases, and hospitalization time. Moreover, we collected data about the different consumed medications including Atrovastatin 20 mg, Atrovastatin 40 mg, Ivermectin 3 mg, Ivermectin 40 mg, Dexamethasone, Kaletra, Favipiravir, Famotidine 40 mg, Interferon, Remdesivir, Hydroxychloroquine.
- Categories:
395 Views
During our research in generating or optimizing molecules to be drug candidates by extending deep reinforcement learning and graph neural networks algorithms, we used GEOM data [1], and we had an idea to make a dataset obtained from molecules from GEOM to predit the activity towards COVID and the drug linkeness. We calculated over 200 descriptors for the molecules using RDKit [2]. We hope you enjoy using it.
References:
- Categories:
370 Views