Artificial Intelligence

This paper introduces a new dataset named CSED, designed for Chinese cybersecurity ED. The dataset has collected approximately 18,000 news articles related to cybersecurity. We have drawn on the classification definitions of cybersecurity event types from the CAISE [38] , defining two event types: Attack and Vulnerability, and further subdividing them into nine sub-event types: Data Breach, Phishing, Ransom, DDoS Attack, Malware, Supply Chain, Vulnerability Impact, Vulnerability Discovery, and Vulnerability Patch.
- Categories:
 426 Views
426 Views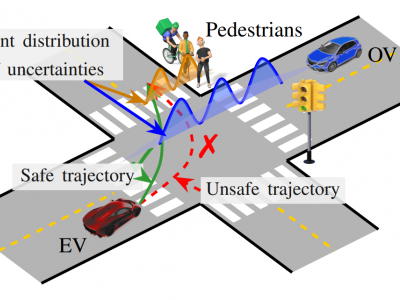
This paper develops a correct-by-design controller for an autonomous vehicle interacting with opponent vehicles with unknown intentions. We define an intention-aware control problem incorporating epistemic uncertainties of the opponent vehicles and model their intentions as discrete-valued random variables. Then, we focus on a control objective specified as belief-space temporal logic specifications. From this stochastic control problem, we derive a sound deterministic control problem using stochastic expansion and solve it using shrinking-horizon model predictive control.
- Categories:
366 Views
This dataset contain the pulse responses of the Tow-Thomas filter circuit, CSTV filter circuit and the four-op-amp biquadratic filter circuit. The test excitation is a 10 us pulse signal with an amplitude of 5 V and a frequency of 5 kHZ that exhibits abundant frequency components. By observing the pulse response, the sampling frequency is set to 5 MHz and the number of sampling points for each sample is fixed at 1000 in Case 1. PSPICE is applied for circuit simulation to set up the circuit fault according to the range of fault component parameter values.
- Categories:
134 Views
In this dataset we release the data of a sequence of boxes that go through a physical binary sorter that acts as a load balancer between warehouses. This particular physical binary sorter works in real-time operating 4.5 million boxes per year. This is a particular example for a company with hundreds of \textit{physical binary sorters} that are central to the internal logistics of the business.
- Categories:
753 Views
As the world increasingly becomes more interconnected, the demand for safety and security is ever-increasing, particularly for industrial networks. This has prompted numerous researchers to investigate different methodologies and techniques suitable for intrusion detection systems (IDS) requirements. Over the years, many studies have proposed various solutions in this regard, including signature-based and machine learning (ML)-based systems. More recently, researchers are considering deep learning (DL)-based anomaly detection approaches.
- Categories:
346 Views
This dataset comprises high-resolution imaging data of biological porcine, clinically approved porcine and bovine, and chick embryo heart tissues. The dataset includes comprehensive anatomical and structural details, making it valuable for research in cardiovascular biology, tissue engineering, and computational modeling. The porcine and bovine heart samples are clinically approved, ensuring relevance for translational and preclinical studies. The chick embryo heart data provides insights into early cardiac development.
- Categories:
103 Views
This dataset is the outcome of an observation on Millet traits under seed coating and covering. For covering we rely on Germination Percentage (FGP), Germination Index (GI),Mean Germination Time (MGT), Seedling Length( SL) and Seedling Vigour Index (SVI) and Abnormal Seedling have been measured. Moreover, different enzyme levels including catalase, peroxidase, and Malondialdehyde (MDA) are measured.
- Categories:
168 Views
This dataset consists of 737 documents from the BBC Sport website, corresponding to sports news articles in five topical areas from 2004-2005. The class labels are divided into five categories: athletics, cricket, football, rugby, and tennis. The datasets have been pre-processed using the Porter stemming algorithm, stop-word removal, and filtering out terms with low frequency (count < 3).
- Categories:
243 Views
This dataset contain the pulse responses of the Sallen-Key bandpass filter circuit and the amplifier board circuit. The test excitation is a 10 us pulse signal with an amplitude of 5 V and a frequency of 5 kHZ that exhibits abundant frequency components. By observing the pulse response, the sampling frequency is set to 5 MHz and the number of sampling points for each sample is fixed at 1000 in Case 1. PSPICE is applied for circuit simulation to set up the circuit fault according to the range of fault component parameter values.
- Categories:
121 Views
These are tight pedestrian masks for the thermal images present in the KAIST Multispectral pedestrian dataset, available at https://soonminhwang.github.io/rgbt-ped-detection/
Both the thermal images themselves as well as the original annotations are a part of the parent dataset. Using the annotation files provided by the authors, we develop the binary segmentation masks for the pedestrians, using the Segment Anything Model from Meta.
- Categories:
648 Views