Artificial Intelligence

Livox-3DMatch contains 11 scenes with 33 scans. Livox-3DMatch augments the original 3DMatch training data from 14,400 pairs to 17,700 pairs (a 22.91% increase). By training on this augmented dataset, the performance of the SOTA learning-based method SGHR is improved by 2.90% on 3DMatch,4.29% on ETH, and 22.72% (translation) / 11.19% (rotation) on ScanNet.
- Categories:
 452 Views
452 Views
Efficient and realistic tools capable of modeling radio signal propagation are an indispensable component for the effective operation of wireless communication networks. The advent of artificial intelligence (AI) has propelled the evolution of a new generation of signal modeling tools, leveraging deep learning (DL) models that learn to infer signal characteristics.
- Categories:
1736 Views
The dataset includes 22 projects and 1680 user stories, with the aim of classifying these stories into those suitable for AI implementation and those not recommended for AI implementation. The labeling was done in a group, reaching a consensus on each user story in each project, determining whether it is susceptible to being developed with AI. Thus, each user story was evaluated and assigned a value of 1 if it was considered suitable for AI implementation (this label was named AI), and a value of 0 if it was not (this label was named not-AI).
- Categories:
615 Views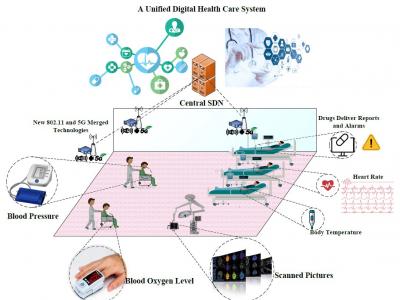
Abstract—In recent years, there has been a significant advancement
in the field of healthcare systems with the introduction
of fifth generation cellular communications and beyond (5GB).
This development has paved the way for the utilization of
telecommunications technologies in healthcare systems with an
level of certainty, reaching up to 99.999 percent. In this paper,
we present a novel task computing framework that can address
the requirements of healthcare systems, such as reliability. In
- Categories:
323 Views
Tea is a significant economic product in our country, and tea plantation harvesting constitutes an essential agricultural activity. The tea plantation picking work is gradually moving towards intelligence and mechanization. As an active research field, artificial intelligence recognition technology is expected to identify the large-scale tea plantation picking work that is being promoted under the current situation, as well as the identification of tea plantation picking behavior.
- Categories:
348 Views
The dataset contains 560 different observations each having 1049 absorption data points for cancerous and non-cancerous skin cells. The reflection absorption data were obtained from terahertz metamaterials on top of which the cells are placed. The 560 observations made were for varying size tissue thickness and polarization and incident wave angle
- Categories:
447 Views
The Electrical Storm Optimization (ESO) algorithm, inspired by the dynamic nature of electrical storms, is a novel population-based metaheuristic that employs three dynamically adjusted parameters: field resistance, intensity, and conductivity. Field resistance assesses the spread of solutions within the search space, reflecting strategy diversity. Field intensity balances the exploration of new territories and the exploitation of promising areas. Field conductivity adjusts the adaptability of the search process, enhancing the algorithm's ability to escape local optima.
- Categories:
115 Views
Federated Learning (FL) as a promising distributed machine learning paradigm has been widely adopted in Artificial Intelligence of Things (AIoT) applications. However, the efficiency and inference capability of FL is seriously limited due to the presence of stragglers and data imbalance across massive AIoT devices, respectively. To address the above challenges, we present a novel asynchronous FL approach named CaBaFL, which includes a hierarchical \textbf{Ca}che-based aggregation mechanism and a feature \textbf{Ba}lance-guided device selection strategy.
- Categories:
63 Views
We introduce two novel datasets for cell motility and wound healing research: the Wound Healing Assay Dataset (WHAD) and the Cell Adhesion and Motility Assay Dataset (CAMAD). WHAD comprises time-lapse phase-contrast images of wound healing assays using genetically modified MCF10A and MCF7 cells, while CAMAD includes MDA-MB-231 and RAW264.7 cells cultured on various substrates. These datasets offer diverse experimental conditions, comprehensive annotations, and high-quality imaging data, addressing gaps in existing resources.
- Categories:
1042 Views
This is a handwritten Chinese signatures dataset including offline images, online sequences and hand videos.
The TMS dataset consists of 70 writers, each contributing 10 multimodal genuine signatures and 20 people have additional 10 forgeries.
The dataset includes 90 subfiles (each for an individual writer) and a python file which processes the data. The name of forgery signature file starts with "F_". Each subfile includes 10 static images, 10 dynamic sequences and 10 videos.
(1) Images are in size of 1278×798 with RGBA channel, and stored in PNG format.
- Categories:
338 Views