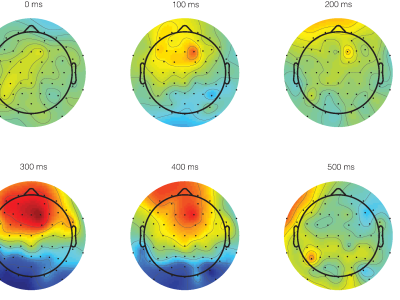
This data set consists of 3-phase currents of faults and other transient cases for transmission lines connected with DFIG-based Wind Farms. PSCAD/EMTDC software is used for the simulation of the faults and other transients.
- Categories:
This data set consists of 3-phase currents of faults and other transient cases for transmission lines connected with DFIG-based Wind Farms. PSCAD/EMTDC software is used for the simulation of the faults and other transients.

Several experimental measurement campaigns have been carried out to characterize Power Line Communication (PLC) noise and channel transfer functions (CTFs). This dataset contains a subset of the PLC CTFs, impedances, and noise traces measured in an in-building scenario.
The MIMO 2x2 CTFs matrices are acquired in the frequency domain, with a resolution of 74.769kHz, in the frequency range 1 - 100MHz. Noise traces, in the time domain with a duration of about 16 ms, have been acquired concurrently from the two multi-conductor ports.
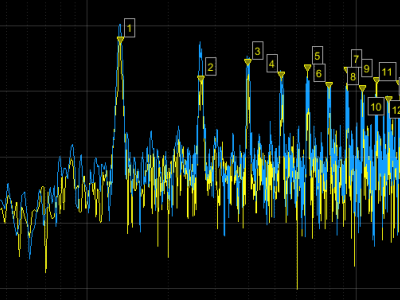
This dataset is in support of my research paper 'Comparison of ElectroMagnetic Emissions & Harmonic Analysis of 20 HP Motor Controlled by 3L NPC Inverter'.
Preprint : https://doi.org/10.36227/techrxiv.19687041.v1
This is useful for manufacturers and r&d engineers for product costing. For more information, results, conclusions on this, pls read research paper.

Radio-frequency noise mapping data collected from Downtown, Back Bay and North End neighborhoods within Boston, MA, USA in 2018 and 2019.
Speech Processing in noisy condition allows researcher to build solutions that work in real world conditions. Environmental noise in Indian conditions are very different from typical noise seen in most western countries. This dataset is a collection of various noises, both indoor and outdoor ollected over a period of several months. The audio files are of the format RIFF (little-endian) data, WAVE audio, Microsoft PCM, 8 bit, mono 11025 Hz and have been recorded using the Dialogic CTI card.
We present two synthetic datasets on classification of Morse code symbols for supervised machine learning problems, in particular, neural networks. The linked Github page has algorithms for generating a family of such datasets of varying difficulty. The datasets are spatially one-dimensional and have a small number of input features, leading to high density of input information content. This makes them particularly challenging when implementing network complexity reduction methods.