Machine Learning

Conveyor belts are the most widespread means of transportation for large quantities of materials in the mining sector. This dataset contains 388 images of structures with and without dirt buildup.
One can use this dataset for experimentation on classifying the dirt buildup.
- Categories:
 1170 Views
1170 Views
This dataset covers cellular communication signals in the SCF format. There is a total of 60000 signal instances, 36000 of them are reserved as training data and the rest is for the test. The SNR levels are between 1 dB and 15 dB.
- Categories:
5439 Views

Dataset for Telugu Handwritten Gunintam
- Categories:
656 Views
This dataset is part of my PhD research on malware detection and classification using Deep Learning. It contains static analysis data: Top-1000 imported functions extracted from the 'pe_imports' elements of Cuckoo Sandbox reports. PE malware examples were downloaded from virusshare.com. PE goodware examples were downloaded from portableapps.com and from Windows 7 x86 directories.
- Categories:
7682 Views
This dataset is part of my PhD research on malware detection and classification using Deep Learning. It contains static analysis data: Raw PE byte stream rescaled to a 32 x 32 greyscale image using the Nearest Neighbor Interpolation algorithm and then flattened to a 1024 bytes vector. PE malware examples were downloaded from virusshare.com. PE goodware examples were downloaded from portableapps.com and from Windows 7 x86 directories.
- Categories:
3406 Views
This dataset comes up as a benchmark dataset for machines to automatically recognizing the handwritten assamese digists (numerals) by extracting useful features by analyzing the structure. The Assamese language comprises of a total of 10 digits from 0 to 9. We have collected a total of 516 handwritten digits from 52 native assamese people irrespective of their age (12-86 years), gender, educational background etc. The digits are captured in .jpeg format using a paint mobile application developed by us which automatically saves the images in the internal storage of the mobile.
- Categories:
1206 Views
This dataset is part of my PhD research on malware detection and classification using Deep Learning. It contains static analysis data (PE Section Headers of the .text, .code and CODE sections) extracted from the 'pe_sections' elements of Cuckoo Sandbox reports. PE malware examples were downloaded from virusshare.com. PE goodware examples were downloaded from portableapps.com and from Windows 7 x86 directories.
- Categories:
3092 Views
An accurate and reliable image-based quantification system for blueberries may be useful for the automation of harvest management. It may also serve as the basis for controlling robotic harvesting systems. Quantification of blueberries from images is a challenging task due to occlusions, differences in size, illumination conditions and the irregular amount of blueberries that can be present in an image. This paper proposes the quantification per image and per batch of blueberries in the wild, using high definition images captured using a mobile device.
- Categories:
2586 Views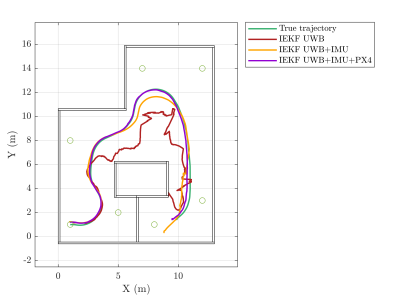
This dataset includes the measurements of a simulated vehicle inside a Gazebo simulation using different sensors: a simulated UWB tag, a IMU and a PX4Flow.
- Categories:
1162 Views