Excel

Contributions: This study offers valuable insights to MOOC designers about user priorities associated with web accessibility principles for designing web content that provides higher levels of user experience, motivating course completions. Background: MOOCs improve access to quality education. Despite policy support and more involvement by leading educational institutions worldwide, poor course completion rates undermine the objectives for MOOC diffusion.
- Categories:
 8 Views
8 Views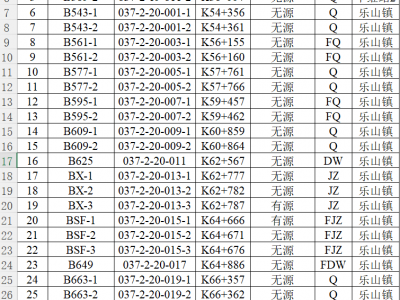
CTCS-2 level train control engineering data is primarily categorized into trackside infrastructure data and line parameters, including line velocity table, line gradient table, line broken chain detail table, balise position table, main line signal data table and so on. The dataset image above is an example of a balise position table.
- Categories:
238 Views
The SaudiShopInsights dataset is a comprehensive collection of customer reviews in the Arabic language, specifically focusing on the Saudi dialect, within the domains of fashion and electronics. Gathered from various online platforms, this dataset serves as a valuable resource for researchers and practitioners interested in sentiment analysis, natural language processing, and customer behavior studies.
- Categories:
485 Views
The dataset includes on-state saturation voltage information for eight samples under four different test conditions. Each Excel file consists of two data columns: one for cycle numbers and the other for on-state saturation voltage. Although these data were collected during the power cycling test at the maximum junction temperature, the effect of temperature increase in the on-state voltage has been compensated. Namely, the provided on-state voltage has been unified to the corresponding to the respective 125°C or 150°C.
- Categories:
718 Views
This dataset contains the input and output data from an industrial case study aiming to detect undesired non-intuitive behavior in an engineered complex system (an Autonomous Surface Vessel (ASV) on a Search and Rescue (SAR) mission). We used the Taguchi method to set up experiments, conducted the experiments in a case company specific test arena, and performed different forms of regression analysis.
- Categories:
36 Views
Compared with traditional finance, digital finance introduces digital technology for financial innovation, which largely reduces financial exclusion and discrimination, but improved financial services, such as mobile payment, online lending, virtual currency, and investment and wealth management, also involve potential risks. Hence, we propose a sentiment analysis model, GABP-News, to study the predictive ability of the information contained in news texts on digital financial development in China.
- Categories:
289 Views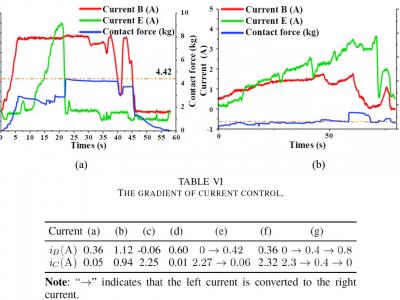
To address the current problem of decoupling between joints and the fixed synergy relationship of underactuated fingers, an adaptive and dexterous underactuated finger named the LMH finger was designed in this paper.
- Categories:
150 Views
We employed a case study research approach to gather the factors for troubled software projects from the existing literature to generate an innovative dataset. A comprehensive dataset that serves as a foundational reference for future investigations. We extracted incidents from case study data, generated open codes, and organized these open codes into 18 problem categories and 27 solution categories. The mapping between open codes, axial codes and phases is documented in dataset. The codes encapsulate the behavioral patterns or actions of a team that initiate or cause is
- Categories:
Views
RMUTT-DLD is an aggregated collection of data that encompasses details derived from the IC3 digital literacy certification program conducted at Rajamangala University of Technology Thanyaburi (RMUTT) in Thailand spanning from 2016 to 2023. The expanded dataset includes demographic details, academic records, and certification results, offering a holistic perspective on the progression of students' digital literacy over a period of time. The dataset has the flexibility to be imported into diverse applications, enabling its utilization for various purposes.
- Categories:
477 Views
This is the data of an innovative microstepping motor controller with excitation angular current double-loop feedback control (ACDL), and compared with the data of a conventional stepper motor controller (OP) and angle closed-loop control (AL).
- Categories:
61 Views