CSV

The extraction and construction of high-precision and long-distance vehicle trajectory data and microscopic traffic flow characteristics are critical for traffic safety studies. Current research typically relies on a limited number of datasets which suffer from vehicle detection inaccuracy and limitation of the coverage area. Therefore, we establish a high-precision and long-distance vehicle trajectory dataset of urban scenarios, which is also named as WUT-NGSIM.
- Categories:
 1683 Views
1683 Views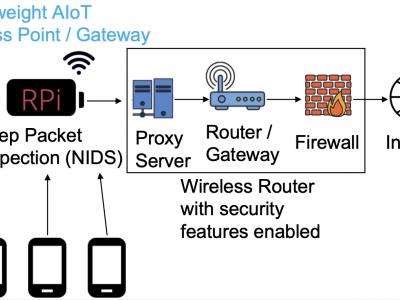
Datsets and scripts are for derivation of a lightweight AIoT malware detection model.
- Categories:
484 Views
Data Description:
- Categories:
11466 Views
Several fields of study can benefit from a large, structured, and accurate dataset of historical figures. Due to a lack of such a dataset, in this paper, we aim to use machine learning and text mining models to collect, predict, and cleanse online data with a focus on age and gender. We developed a five-step method and inferred birth and death years, binary gender, and occupation from community-submitted data to all language versions of the Wikipedia project.
- Categories:
1199 Views
A conventional virtual flight test generally refers to a 3-DOF dynamic flight test in a wind tunnel. In the wind tunnel test, the model aircraft is connected to the strut through a 3-DOF rotation mechanism and installed in the wind tunnel test section so that the model displacement is constrained but has 3 degrees of angular motion freedom. Open-loop and closed-loop control of the aircraft model is achieved by directly driving the rudder surface or by using commands from the flight control system.
- Categories:
240 Views
Data for neural networks.
Magnetic flux intensity - input
The real pose of a single magnet - output
- Categories:
232 Views
The dataset consists of three parts, the first part consists of single notes and playing technique samples, and the second includes the triple viewed video, steoro-microphone recordings and 4 track optical vibration recordings in raw file for famous Chinese Folk music ‘Jasmine Flower’ and the first section of ‘Ambush from ten sides’. The third part concerns about the source separated tracks from optical recordings and expressive annotation files are included in the annotation files.
- Categories:
100 Views
We collect IMU measurements under three different patterns: Fixing a smartphone in front of his chest (chest), swing a smartphone while holding it in his hand (swing), and putting a smartphone in his pocket (pocket). We use Google Pixel 3XL for the pattern of chest and Google Pixel 3a for the patterns of swing and pocket. The sampling frequency of each measurement is fixed to 15Hz. We collect the measurement of 111 paths in total, categorized into 4 types. We partition them into 84 and 27 paths, used for training and testing, respectively. It takes 10 hours to collect all datasets.
- Categories:
211 Views
Document layout analysis (DLA) plays an important role for identifying and classifying the different regions of digital documents in the context of Document Understanding tasks. In light of this, SciBank seeks to provide a considerable amount of data from text (abstract, text blocks, caption, keywords, reference, section, subsection, title), tables, figures and equations (isolated equations and inline equations) of 74435 scientific articles pages. Human curators validated that these 12 regions were properly labeled.
- Categories:
2140 Views
Understanding the properties of grain boundaries in polycrystalline superconductors is essential for optimizing their critical current density. Here, we provide computational simulations of 2D Josephson junctions (JJs) in low magnetic fields using time--dependent Ginzburg--Landau theory, since they can be considered a proxy for a grain boundary between two grains.
- Categories:
45 Views