CSV

The raw data from Artsy (from https://www.artsy.net/ ) were collected using the original Python scraping program. Artsy labeled the categories as follows: "Painting", "Work on Paper", "Sculpture", "Print", "Photography", and "Textile Arts". These categories were predicted by other explanatory variables. The rationale behind the selection of this task is the price levels differ greatly across the various categories.
- Categories:
 39 Views
39 Views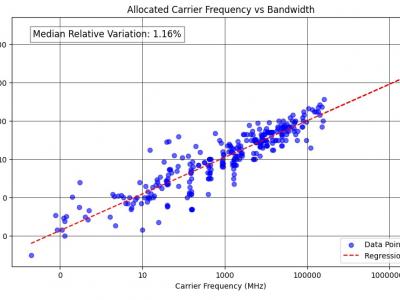
The dataset derived from the European Table of Frequency Allocations (ECA Table) represents a comprehensive compilation of frequency ranges and their associated bandwidths allocated for various applications across the electromagnetic spectrum, spanning from 8.3 kHz to 3000 GHz. This dataset is of interest to gain an understanding the distribution of frequency allocations and bandwidth usage in a regulatory framework, aiding in spectrum management and planning.
- Categories:
276 Views
Despite the considerable efforts to enhance road infrastructure and enforce stricter driving regulations to ensure road safety, the number of accidents worldwide remains alarmingly high, driven by factors such as distracted driving, speeding, and impaired driving. For instance, in the United States, fatal accidents increased by 16% from 2018 to 2022, with the number of fatalities rising from 36,835 in 2018 to 42,795 in 2022. This highlights the pressing need for innovative solutions to mitigate traffic incidents and enhance road safety.
- Categories:
254 Views
As the world increasingly becomes more interconnected, the demand for safety and security is ever-increasing, particularly for industrial networks. This has prompted numerous researchers to investigate different methodologies and techniques suitable for intrusion detection systems (IDS) requirements. Over the years, many studies have proposed various solutions in this regard, including signature-based and machine learning (ML)-based systems. More recently, researchers are considering deep learning (DL)-based anomaly detection approaches.
- Categories:
346 Views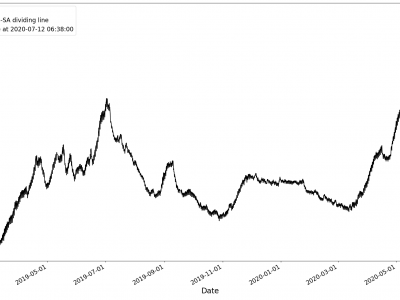
Missing values in the dataset were denoted as 999999.0. After replacing 999999.0 with NAN, it was found that the Zhaogezhuang well had 4522 missing values, and the Yutian Ji 03 well had 2076 missing values. Linear interpolation was used to fill these missing values. The datasets after filling are shown in Figures. The red dashed line in the figure indicates the dates that separate the seismically Active (SA) and seismically inactive (non-SA) periods.
- Categories:
357 Views

Arc faults are a significant cause of failure in photovoltaic (PV) system and can arise due to component deterioration, installation problems, rodents chewing on wires, abrasion of insulation, or other root causes. Undetected, incipient arc faults can propagate into electrical fires. Consequently, arc-fault detectors, now mandated in many jurisdictions, are essential for safe operation of PV systems.
- Categories:
687 Views
Dataset Description
A dataset containing data collected from measuring the drift characteristics titanium dioxide memristors, for a variety of initial states, under zero-bias conditions.
The devices used were TiO2 devices, with Al2O3 interstitials - the same device type as used in [1].
Data Collection
Devices were electroformed using a series of steadily increasing voltage pulses, ranging in magnitude from 3V to 10V with a step of 0.5V. The electroforming pulse widths ranged from 10µs to 100µs.
- Categories:
68 Views
Near-field microwave detection plays a crucial role in various applications such as medical diagnosis, non-destructive and electromagnetic compatibility (EMC) tests. This dataset presents the original data of the microwave sensor exploiting the magnon-photon coupling properties. This scheme offers a novel approach to microwave metrology with promising applications in microwave imaging, EMC tests, and integrated circuit design.
- Categories:
19 Views
Along with the continuous growth of Internet usage, mobile users are becoming increasingly relevant as they are responsible for the largest percentage of web traffic. Conse- quently, a large and growing body of literature has been based on cellular data to gain a deeper understanding of several Internet-related concerns. Nevertheless, accessing high-quality cellular datasets can be a challenge for research teams due to scarcity and restricted access.
- Categories:
233 Views