CSV

Dataset Description
A dataset containing data collected from measuring the drift characteristics titanium dioxide memristors, for a variety of initial states, under zero-bias conditions.
The devices used were TiO2 devices, with Al2O3 interstitials - the same device type as used in [1].
Data Collection
Devices were electroformed using a series of steadily increasing voltage pulses, ranging in magnitude from 3V to 10V with a step of 0.5V. The electroforming pulse widths ranged from 10µs to 100µs.
- Categories:
 53 Views
53 Views
The JKU-ITS AVDM contains data from 17 participants performing different tasks with various levels of distraction.
The data collection was carried out in accordance with the relevant guidelines and regulations and informed consent was obtained from all participants.
The dataset was collected using the JKU-ITS research vehicle with automated capabilities under different illumination and weather conditions along a secure test route within the
- Categories:
701 Views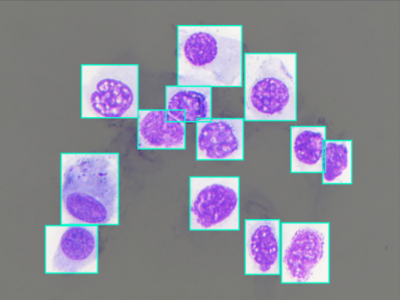
Nasal Cytology, or Rhinology, is the subfield of otolaryngology, focused on the microscope observation of samples of the nasal mucosa, aimed to recognize cells of different types, to spot and diagnose ongoing pathologies. Such methodology can claim good accuracy in diagnosing rhinitis and infections, being very cheap and accessible without any instrument more complex than a microscope, even optical ones.
- Categories:
637 Views
a Sinkhole attack in a dataset, we'll generate data that typically reflects network traffic and interactions, where some nodes act as sinkholes by attracting all or most of the traffic due to malicious intent. Here's how I'll structure the dataset for 80,000 records:
- Categories:
299 Views
a dataset with 50,000 records simulating a Sybil attack scenario. Here's the plan for each record in the dataset:
- Categories:
340 Views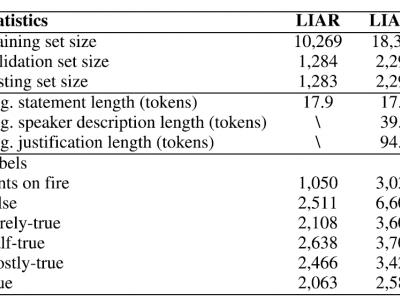
The LIAR dataset has been widely followed by fake news detection researchers since its release, and along with a great deal of research, the community has provided a variety of feedback on the dataset to improve it. We adopted these feedbacks and released the LIAR2 dataset, a new benchmark dataset of ~23k manually labeled by professional fact-checkers for fake news detection tasks.
- Categories:
195 Views
The datasets comprise configurations of loading and unloading plans for container ships, generated under six distinct scenarios based on varying numbers of stacks and maximum stack heights of containers in each row. Considering typical container ship characteristics, scenarios encompass stack numbers ranging from 5 to 30 and maximum stack heights from 4 to 10. The dataset includes loading and unloading plans for dockyard containers, with sample plans provided for small ships. Each of the 5 datasets comprises 20 instances representing different container loading and unloading scenarios.
- Categories:
178 Views
This dataset contains the online appendix of the paper titled "The effectiveness of hidden dependence metrics in bug prediction"
Abstract:
- Categories:
79 Views
Raw datasets of PDA10A receiver signals acquired with MSO2024 oscilloscope for Time Difference of Arrival Optical Wireless Positioning measurements.
The data is stored in csv, numpy and pickle format to be easily imported and processed in Python.
The first dataset consists of measurements on a grid without reflections.
The second dataset are identical measurements but with a corner geometry at the fourth receiver creating diffuse reflections.
- Categories:
74 Views
The Reflection Server Tuning dataset contains HiPerConTracer latency measurements performed in a lab setup. The purpose of the dataset is to measure the latency and jitter effects of firewalls and Linux kernel tuning.
- Categories:
247 Views