Social Sciences

Digital transformation provides new opportunities for corporate innovation and becomes a new engine for high-quality and sustainable economic development. The dataset can be used with Excel software to filter the data and Stata software to process the data. Manufacturing is the main track of digital transformation in China. THE Dataset include all A-share listed manufacturing corporates in China from 2011-2022. Since the earliest digital transformation data of Chinese manufacturing corporates were generated in 2011, the data start date is set at 2011.
- Categories:
 97 Views
97 Views
This dataset contains results from a comparative simulation of blockchain-enabled trade systems and traditional trade mechanisms across five global trade hubs: the USA, China, Germany, Japan, and India. The dataset includes information on 10,000 simulated transactions, focusing on key metrics such as processing time, transaction costs, failure rates, and resilience to risk events.
- Categories:
77 Views
To download this dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13896353
Please cite the following paper when using this dataset:
- Categories:
982 Views
This dataset is a network representation of authors linked to the publications they have authored or co-authored, collected from OpenAlex.org using the free, open-source tool available at https://openalex4nodexl.netlify.app/. It is provided as a CSV flat file, formatted for use with NodeXL, a popular tool for social network analysis.
- Categories:
173 Views
We gathered a total of 1,515 news articles concerning suicide, building jumps, and related incidents from 2019 to 2024. Utilizing sentiment analysis tools, we categorized the data into two groups: positive sentiment words and negative sentiment words. Our primary objective was to examine the relationship between negative sentiment words and other associated terms.
- Categories:
181 Views
The UNISTUDIUM dataset contains the logs collected by Unistudium, the University of Perugia elearning platform based on moodle, a open source software for learning management systems (https://moodle.org).
The collected logs record interactions with the platform of students attending 4 courses during the time period of one semester, from 1st September to 31st December.
- Categories:
192 Views
To download the dataset without purchasing an IEEE Dataport subscription, please visit: https://zenodo.org/records/13738598
Please cite the following paper when using this dataset:
- Categories:
1299 Views
The Protection of Children from Sexual Offences (POCSO) Act was an important legislation that was enacted in India in 2012. It aims to safeguard children from sexual exploitation through various enforcement and legal redressal mechanisms. This dataset has been scraped from eCourts India Services using Python script which uses Selenium. We have mined apex and high courts’ judgements, which mentioned the POCSO Act and its respective sections. We have chronologically scraped POCSO judgements from 2012 to 2020 in the corpus.
- Categories:
453 Views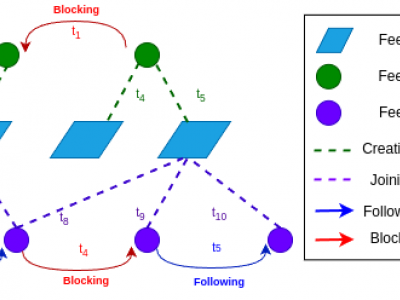
Decentralized social media platforms like Bluesky Social (Bluesky) have made it possible to publicly disclose some user behaviors with millisecond-level precision. Embracing Bluesky's principles of open-source and open-data, we present the first collection of the temporal dynamics of user-driven social interactions. BlueTempNet integrates multiple types of networks into a single multi-network, including user-to-user interactions (following and blocking users) and user-to-community interactions (creating and joining communities).
- Categories:
1187 Views
The dataset includes Pakistan most popular YouTube videos for each category from year 2021- 2023. There are two kinds of data files, one includes video statistics and other one related to comments on those videos. They are linked by the unique video_id field. Both datasets are merged in final videos file which contains all videos statistics and sentiment extracted from comments. Here’s a breakdown of each column:
- Categories:
319 Views