Social Sciences

1.Cora dataset is derived from a multi-group citation network, and the two-group subgraphs are selected for tasks such as graph neural network node classification. The dataset contains sparse Bag-of-Words feature vectors as node attributes, and the labels are mostly academic paper topic categories or fields. This subgraph focuses on the influence of graph structure and node characteristics on model prediction, which provides a reliable experimental benchmark for the research of multi-step adversarial attacks and defense strategies.
- Categories:
 79 Views
79 Views
This dataset supports the structural equation modeling (SEM) analysis of the impact of emerging IT integration on supply chain resilience. The data were collected using a snowball sampling method, initially distributed to EMBA students at Northwestern Polytechnical University and Xidian University, who were encouraged to share the survey link within their professional networks.
- Categories:
20 Views
This study focuses on building resilience in electric vehicle (EV) supply chain to address the growing challenges of global market uncertainties. Grounded in dynamic capabilities theory, the study identifies and categorizes 16 key factors influencing Supply Chain Resilience (SCR) through a review of 117 academic papers and data analysis from 8 supply chain experts and 374 EV sup-ply chain enterprises.
- Categories:
43 Views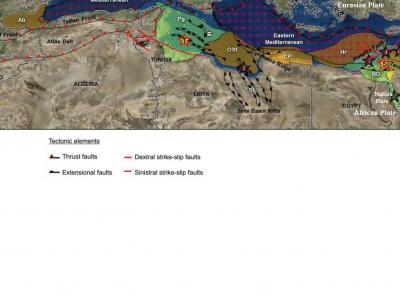
Northern Africa and the Eastern Mediterranean area has faced lots of natural catastrophes to earthquakes last decade. The primary active tectonic structure concentrated in Sub-Saharan Africa. A recent assessment of earthquake seismicity characteristics has been conducted in North Africa.The database of historical and instrumental earthquakes is one of the most crucial tools for evaluating the risk of earthquakes.
- Categories:
251 Views
Two Approaches to Constructing Certified Dominating Sets in Social Networks: R Script Description
This script implements and analyzes various algorithms for graph processing, focusing on domination problems, including double domination and certified dominating sets.
Script Overview
The script generates tree graphs, calculates certified dominating sets using ApproxCert and other algorithms, and evaluates their performance in terms of execution time and results. Results are saved in a CSV file for further analysis.
- Categories:
50 Views
In the digital age, knowledge sharing is gaining increasing significance, but its contribution in promoting the protection and transmission of rural intangible cultural heritage is still not fully appreciated. Based on SOR theory and SET theory, this study takes agricultural digital intangible heritage as the research object to develop a theoretical model on the knowledge sharing intention of agricultural digital intangible heritage.
- Categories:
83 Views
The dataset is a multiplex social network dataset collected from the Department of Computer Science at Aarhus University, Denmark. The total number of nodes in this multilayer network is 61, and the total number of edges in each layer of the network is 620, which is an unweighted and undirected multiplex social network. It captures their relationships across five different types of interactions: Facebook connections, leisure activities, work collaborations, co-authorships, and lunch meetings. Each layer in the network corresponds to a specific type of relationship.
- Categories:
100 Views
To provide machine learning and data science experts with a more robust dataset for model training, the well-known Palmer Penguins dataset has been expanded from its original 344 rows to 100,000 rows. This substantial increase was achieved using an adversarial random forest technique, effectively generating additional synthetic data while maintaining key patterns and features. The method achieved an impressive accuracy of 88%, ensuring the expanded dataset remains realistic and suitable for classification tasks.
- Categories:
378 Views
The Deenz Psychopathy Spectrum Scale (DPSS-24) is a newly developed psychometric instrument aimed at assessing psychopathy traits across diverse adult populations. This study presents preliminary data collected from two distinct samples—a group of 21 participants from an initial testing phase and a German sample of 31 participants. Each participant completed the DPSS-24, a 24-item scale designed to measure various psychopathy-related behaviors, including impulsivity, emotional detachment, and interpersonal difficulties, using a Likert scale ranging from 1 to 5.
- Categories:
96 Views
The equity structure forms the foundation of the governance framework, while the incentive and constraint mechanisms are at its core. Together, they establish a complete corporate governance system. This study takes listed companies in the textile industry on the Shanghai and Shenzhen A-share markets in China as the sample.
- Categories:
31 Views