Social Sciences
We sourced our data by crawling comments from the “Zoufan” blog within the Weibo social platform. Subsequently, a team of qualified psychologists were enlisted to annotate the data. In our study, strict data preprocessing measures were adopted to protect users’ privacy.
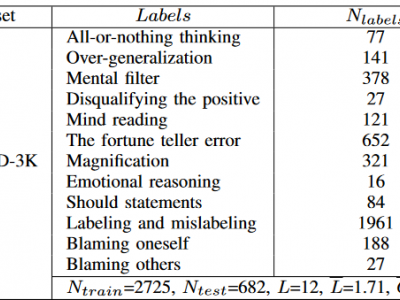
SocialCD-3K (Cognitive Distortion Classification)
- Categories:
 359 Views
359 Views
We sourced our data by crawling comments from the “Zoufan” blog within the Weibo social platform. Subsequently, a team of qualified psychologists were enlisted to annotate the data. In our study, strict data preprocessing measures were adopted to protect users’ privacy.
SOS-HL-1K (Suicide Risk Classification)
- Categories:
122 Views
In this paper, we cover the creation of Fantasy Forecast, a gamified forecasting platform used for hosting forecasting competitions, or ‘tournaments’ that was deployed in the run-up to and over the course of the 2023 UK local elections. This research is an interdisciplinary endeavour, gamifying the humanities to create a platform centred on elections and other political phenomena, informed by both quantitative (site use metrics and survey responses) and qualitative (user feedback) data.
- Categories:
47 Views
Interest-based e-commerce survey data. The questionnaire consists of seven sections: The first part includes seven questions about respondents' basic information and platform usage behavior, aimed at determining if the respondents are suitable for this study. The second to seventh parts pertain to the measurement of research variables, covering user interactions, interactions with celebrities, visual appeal, perceived enjoyment, purchase intention, and self-indulgence, totaling 24 questions.
- Categories:
114 Views
This dataset focuses on the redevelopment and psychometric evaluation of the Adversity Response Profile for Indian Higher Education Institution (ARP-IHEI) students, emphasizing its importance in understanding how individuals respond to adversity. The data were gathered from a sample of 122 second year students at school of computing, MIT Art, Design and Technology University. The psychometric properties were rigorously examined using factor analysis.
- Categories:
67 Views
All data are downloaded from the CSMAR and CNRDS Databases in Excel format. The paper uses panel data from 2011 to 2021, excluding the ST, ST*, and financial companies. After combining them together and excluding the missing value, the valid observation number is 23822, which includes 3021 corporations from 75 industries in China's A-share stock market. The dataset includes the digital transformation score, green patent application number, environmental management disclosure score, institution pressure, and other company-related data, like companies' age, size and profitability.
- Categories:
32 Views
This dataset focuses on the redevelopment and psychometric evaluation of the Adversity Response Profile for Indian Higher Education Institution (ARP-IHEI) students, emphasizing its importance in understanding how individuals respond to adversity. The data were gathered from a sample of 122 second year students at school of computing, MIT Art, Design and Technology University.
- Categories:
118 Views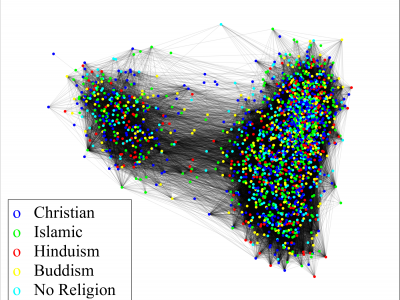
Simulation of the matrix-scaled consensus algorithm [1,2] on the network derived from the dataset socfb-Amherst41 [3,4].
References
[1] Trinh, M. H., Vu, D. V., Tran, Q. V., and Ahn, H.-S. "Matrix-scaled consensus." In Proc. of the 61st IEEE Conference on Decision and Control (CDC), pp. 346-351. IEEE, 2022. arXiv preprint arXiv:2204.10723 (2022)
[2] Trinh, M. H., Vu, H. H., Le-Phan, N.-M., and Nguyen, Q. N. "Matrix-Scaled Consensus over Undirected Networks." arXiv preprint arXiv:2303.14751 (2023).
- Categories:
373 Views
This survey aims to investigate various aspects of employment experiences and career development among individuals across different demographics.
- Categories:
482 Views
Privacy perception refers to the control individuals have over the use of their data, including determining who can access, share, and utilize it without interference or intrusion. In the context of the Internet of Things (IoT), particularly in Smart Home Data Monetization (SH-DM), users’ data is aggregated and made available to potential service providers to target end users with personalized advertisements.
- Categories:
460 Views