Signal Processing

This dataset corresponds to the paper Calibration of a Hail-Impact Energy Electroacoustic Sensor, submitted to IEEE Transactions in Instrumentation and Measurement by Florencia Blasina, Andrés Echarri, and Nicolás Pérez.
The dataset corresponds to the voltage signals acquired regarding several steel-ball impacts on the proposed hail-sensor plate to calibrate it.
- Categories:
 76 Views
76 Views
Experimental measurement data was obtained utilizing RCbenchmark 1780 with full-range PWM signals. Measurements were made for two series of setups.
First series is related to low-voltage setups using the following T-MOTOR components: - motors: MN4014 400Kv, MN5212 340Kv, MN501-S 360Kv, U7 280Kv, MN6007 320Kv, P60 340Kv, MN701-S 280Kv; - ESC: Air 40A, Flame 40A, Flame 70A, Alpha 60A, Flame 100A; - propellers: P17×5.8, P18×6.1, P20×6, P22×6.6, P24×7.2, G26×8.5; - battery: 6-cell (6S) Lithium polymer (LiPo).
- Categories:
151 Views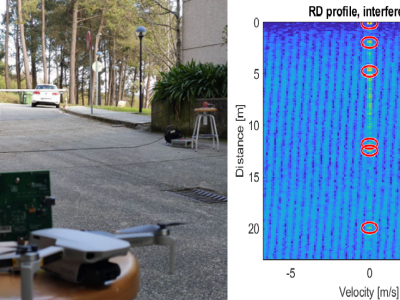
In the attached dataset, a continuous record of 2493 chirp-sequence FMCW radar burst is presented. The data consist of the direct ADC output of an AWR1443BOOST radar board from Texas Instruments during 47.37 s of continuous operation. During this time, two FMCW radars of the model AWR1642BOOST were continuously transmitting sweeps with its main lobe aimed towards the first radar. This produces the apparition of two different uncorrelated interferences at the victim radar side, which can be seen on different indexes of the provided capture.
- Categories:
1566 Views
El carbono orgánico (OC) y el nitrógeno total (N) son
Nutrientes sensibles para el crecimiento de las plantas. La presencia de estos nutrientesEl carbono orgánico (OC) y el nitrógeno total (N) sonOrganic carbon (OC) and total nitrogen (N) are es-Organic carbon (OC) and total nitrogen (N) are sential nutrients for plant growth. The presence of these nutrierganic carbon (OC) and total nitrogen (N) are ews-
w
sential nutrients for plant growth. The presence of these nutrients
in acceptable quantities can generate an optimal environment for
- Categories:
22 Views
The dataset is collected from the xeno-canto website, which is a public website to share bird sounds from around the world . We first collect 15,300 bird sounds from one second to fifteen seconds. Unlike many audio denoising datasets which have manually added artificial noise, our collected bird sounds contain natural noises, including wind, waterfall, rain, etc.
- Categories:
575 Views
This paper investigated how to increase the number of connections among users in hierarchical non-terrestrial networks (HNTNs) assisted disaster relief service (DRS). We aim to maximize the number of satisfactory connections (NSCs) by optimizing the unmanned aerial vehicles (UAV) radio resources, computing resources, and trajectory at each time slot. In particular, the UAVs are exploited as aerial base stations (ABSs) to provide a link for the reduced capability (RedCap) user equipment (UE) based on power domain non-orthogonal multiple access (PD-NOMA).
- Categories:
588 Views
Problems related to ventral hernia are very common, and evaluating them using computational methods can assist in selecting the most appropriate treatment. This study collected data from over 3500 patients from different European countries observed during last 11 years (2012-2022), which were collected by specialists in hernia surgery. The majority of patients underwent standard surgical procedures, with a growing trend towards robotic surgery. This paper focuses on statistically evaluating the treatment methods in relation to patient age, body mass index (BMI), and the type of repair.
- Categories:
231 Views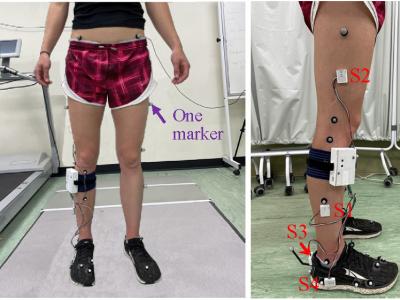
IMUs have gained popularity for tracking joint kinematics due to their portability and versatility. However, challenges such as limited accuracy, lack of real-time data analysis, and complex sensor-to-segment calibration procedures have hindered their widespread use. To address these limitations, we developed a portable system that integrates four IMUs to collect treadmill walking data, with ground truth values obtained from a Motion Capture System.
- Categories:
66 Views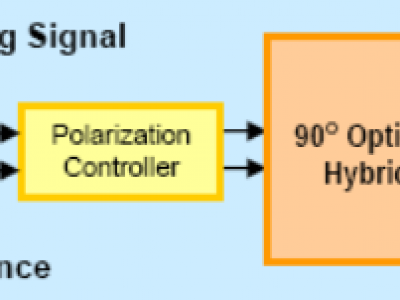
The optical hybrid is mainly used to split and combine the signal beam and the local oscillator beam from two inputs, thereby generating four mixed beams with a relative phase difference of 90°. 90º optical hybrid is suitable for coherent signal demodulation for either homodyne or heterodyne detection. The device accepts the two optical signals (S & L) and generates four output signals: S+L, S-L, S+jL, and S-jL.
- Categories:
20 Views
There are several non-idealities that can degrade magnetic Hall-effect sensors performance and impact related applications. Thus, a confidence weighted learning entropy (CWLE) is proposed as a fault-tolerant control strategy for field-oriented control (FOC) of permanent magnet synchronous machines (PMSM). It combines sensorless and sensor-based control, while capitalizing on their major advantages, such as operation from standstill and at lower speeds, fast dynamic response, and fault tolerance to encoder errors.
- Categories:
130 Views