Machine Learning

As the harmful effects of climate change on human society increase, the analysis of abnormal weather is becoming an important issue. Therefore, this work provides the Korean weather dataset, including the anomaly score measurements by using seven different methods. In this dataset, seven types of weather data for each day in 64 Korean cities from 2010 to 2020 are provided by Weather Radar Center in Korea Meteorological Administration.
- Categories:
 243 Views
243 Views
Low-light images and video footage often exhibit issues due to the interplay of various parameters such as aperture, shutter speed, and ISO settings. These interactions can lead to distortions, especially in extreme lighting conditions. This distortion is primarily caused by the inverse relationship between decreasing light intensity and increasing photon noise, which gets amplified with higher sensor gain. Additionally, secondary characteristics like white balance and color effects can also be adversely affected and may require post-processing correction.
- Categories:
2732 Views
Learning SAR Dataset for Wet Snow Detection - Full Analysis Version.
- Categories:
322 Views
The data included here within is the associated model training results from the correlated paper "Distribution-Driven Augmentation of Real-World Datasets for Improved Cancer Diagnostics With Machine Learning". This paper focuses on using kernel density estimators to curate datasets by balancing classes and filling missing null values though synthetically generated data. Additionally, this manuscript proposes a technique for joining distinct datasets to train a model with necessary features from multiple different datasets as a type of transfer-learning.
- Categories:
35 Views
The data set has been prepared as 2 different versions. The data set was shared in two versions due to the fact that the researchers could easily reproduce the tests and hardware limitations. The first version (small_dataset) was prepared using a 10% sub-sample of all dataset. The other version (big_dataset) contains the entire data. In this study, the scenarios tested were run on the small_dataset. The most successful configuration that was selected as a result of the analysis on small_dataset was applied to big_dataset.
- Categories:
1382 Views
The growing antenna array scale, the uncorrelated fadings between downlink and uplink of frequency division duplex (FDD) or analog beamforming design increases the difficulty of channel sounding or estimation. Non-wireless channel detection or beam weight prediction method is a promising solution to help obtain timely and accurate wireless channel state. Furthermore, beamforming can be enhanced by the powerful sensing capability of cameras.
- Categories:
150 Views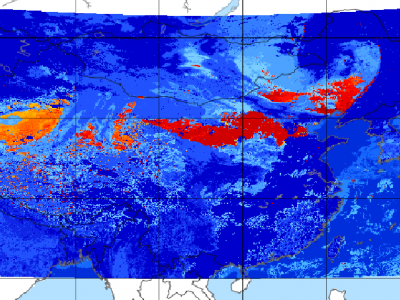
Since meteorological satellites can observe the Earth’s atmosphere from a spatial perspective at a large scale, in this paper, a dust storm database is constructed using multi-channel and dust label data from the Fengyun-4A (FY-4A) geosynchronous orbiting satellite, namely, the Large-Scale Dust Storm database based on Satellite Images and Meteorological Reanalysis data (LSDSSIMR), with a temporal resolution of 15 minutes and a spatial resolution of 4 km from March to May of each year during 2020–2022.
- Categories:
830 Views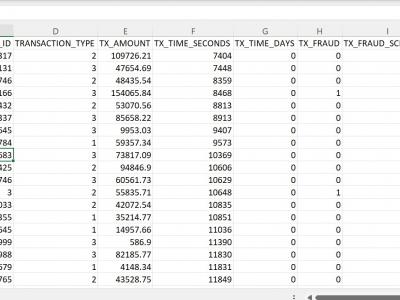
The process of dataset generation comprises three integral components: "Account Profiles," responsible for creating detailed account representations; "Transaction Generation," which simulates a diverse range of financial transactions; and the "Generation of Fraud Scenarios," which introduces predefined templates for identifying potential fraudulent transactions based on various criteria. Together, these components collaboratively construct a dynamic and realistic dataset, mirroring real-world financial systems.
- Categories:
374 Views
Acute myocardial infarction (AMI) is the main cause of death in developed and developing countries. AMI is a serious medical problem that necessitates hospitalization and sometimes results in death. Patients hospitalized in the emergency department (ED) should therefore receive an immediate diagnosis and treatment. Many studies have been conducted on the prognosis of AMI with hemogram parameters. However, no study has investigated potential hemogram parameters for the diagnosis of AMI using an interpretable artificial intelligence-based clinical approach.
- Categories:
1570 Views
The dataset consists of measurements of four different stages of degradation in low-voltage contactors used for industrial purposes. The measurements were obtained with fiber Bragg grating (FBG) sensors that detect the dynamic deformation generated in switching under different internal components. The measurements were processed and features from PSD, FFT and TSFEL python library were extracted. The features of PSD and FFT were acquired in 40 sliding windows of 50Hz from the signal.
- Categories:
152 Views