Machine Learning

- Categories:
 132 Views
132 Views
The JKU-ITS AVDM contains data from 17 participants performing different tasks with various levels of distraction.
The data collection was carried out in accordance with the relevant guidelines and regulations and informed consent was obtained from all participants.
The dataset was collected using the JKU-ITS research vehicle with automated capabilities under different illumination and weather conditions along a secure test route within the
- Categories:
952 Views
This is a compressed package containing nine multi-label text classification data sets, including AAPD, CitySearch, Heritage, Laptop, Ohsumed, RCV1, Restaurant, Reuters, and Sentihood.
- Categories:
190 Views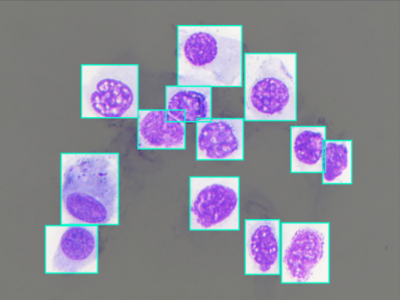
Nasal Cytology, or Rhinology, is the subfield of otolaryngology, focused on the microscope observation of samples of the nasal mucosa, aimed to recognize cells of different types, to spot and diagnose ongoing pathologies. Such methodology can claim good accuracy in diagnosing rhinitis and infections, being very cheap and accessible without any instrument more complex than a microscope, even optical ones.
- Categories:
841 Views
This database contains Synthetic High-Voltage Power Line Insulator Images.
There are two sets of images: one for image segmentation and another for image classification.
The first set contains images with different types of materials and landscapes, including the following landscape types: Mountains, Forest, Desert, City, Stream, Plantation. Each of the above-mentioned landscape types consists of 2,627 images per insulator type, which can be Ceramic, Polymeric or made of Glass, with a total of 47,286 distinct images.
- Categories:
637 Views
To address the challenges faced by patients with neurodegenerative disorders, Brain-Computer Interface (BCI) solutions are being developed. However, many current datasets lack inclusion of languages spoken by patients, such as Telugu, which is spoken by over 90 million people in India. To bridge this gap, we have created a dataset comprising Electroencephalograph (EEG) signal samples of commonly used Telugu words. Using the Open-BCI Cyton device, EEG samples were captured from volunteers as they pronounced these words.
- Categories:
468 Views
The Landsat 8 imagery, sourced from USGS Earth Explorer, covers diverse regions like the northeastern USA snow region, Brazilian forests, UAE deserts, and Indian zones (northern, central, and southern) from 2018 to 2023, capturing long-term trends and seasonal changes. The dataset, including bands B4, B5, and B10 with 30-meter resolution from LANDSAT/LC08/C02/T1\_TOA imagery, is crucial for accurate LST and emissivity prediction models. These bands capture vital land surface properties like vegetation health, moisture, and thermal characteristics, enhancing model reliability.
- Categories:
31 Views
In this work, we download the circRNA-drug sensitivity associations from the circRic database, in which the drug sensitivity data comes from the GDSC database, containing 80076 associations that involve 404 circRNAs and 250 drugs.
- Categories:
9 Views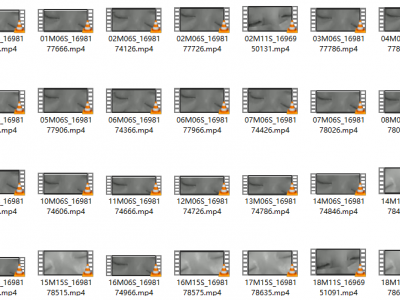
This dataset encapsulates a comprehensive collection of eye movement recordings captured during sleep, exceeding 100 distinct episodes. The recordings are primarily categorized into Rapid Eye Movement (REM), Slow Eye Movement (SEM), and non-movement phases, providing a rich resource for sleep research. Each video is meticulously recorded in high-definition .mp4 format, ensuring clarity and precision in capturing subtle ocular dynamics.
- Categories:
31 Views
- Categories:
234 Views