Machine Learning

The aircraft fuel distribution system has two primary functions: storing fuel and distributing fuel to the engines. These functions are provided in refuelling and consumption phases, respectively. During refuelling, the fuel is first loaded in the Central Reservation Tank and then distributed to the Front and Rear Tanks. In the consumption phase, the two engines receive an adequate level of fuel from the appropriate tanks. For instance, the Port Engine (PE) will receive fuel from Front Tank and the Starboard Engine (SE) will receive fuel from Rear Tank.
- Categories:
 2395 Views
2395 Views
This is the data for paper "Environmental Context Prediction for Lower Limb Prostheses with Uncertainty Quantification" published on IEEE Transactions on Automation Science and Engineering, 2020. DOI: 10.1109/TASE.2020.2993399. For more details, please refer to https://research.ece.ncsu.edu/aros/paper-tase2020-lowerlimb.
- Categories:
1216 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on recognizing textures and materials in real-world images, which plays an important role in object recognition and scene understanding. Aiming at describing objects or scenes with more detailed information, we explore how to computationally characterize apparent or latent properties (e.g. surface smoothness) of materials, i.e., computational material characterization, which moves a step further beyond material recognition.
- Categories:
986 Views
As one of the research directions at OLIVES Lab @ Georgia Tech, we focus on recognizing textures and materials in real-world images, which plays an important role in object recognition and scene understanding. Aiming at describing objects or scenes with more detailed information, we explore how to computationally characterize apparent or latent properties (e.g. surface smoothness) of materials, i.e., computational material characterization, which moves a step further beyond material recognition.
- Categories:
285 Views
The dataset consists of the following columns:
Data description
ColumnDescriptiongift_idUnique ID of giftgift_typeType of gift (clothes/perfumes/etc.)gift_categoryCategory to which the gift belongs under that gift typegift_clusterType of industry the gift belongsinstock_dateDate of arrival of stockstock_update_dateDate on which the stock was updatedlsg_1 - lsg_6Anonymized variables related to giftuk_date1, uk_date2Buyer related datesis_discountedShows whether the discounted is applicable on the giftvolumesNumber of packages boughtpriceThe total price
- Categories:
269 Views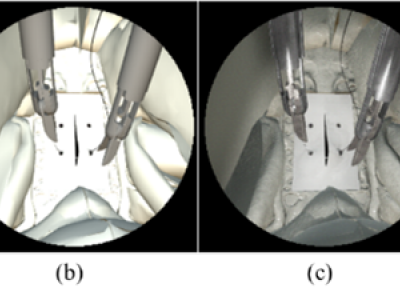
This dataset was used and described in detail in the following publication. The Effects of Different Levels of Realism on the Training of CNNs with only Synthetic Images for the Semantic Segmentation of Robotic Instruments in a Head Phantom. Heredia-Perez, S. A.; Marinho, M. M.; Harada, K.; and Mitsuishi, M. International Journal of Computer Assisted Radiology and Surgery (IJCARS). 2020. https://doi.org/10.1007/s11548-020-02185-0
- Categories:
327 Views
This dataset contains the trained model that accompanies the publication of the same name:
Anup Tuladhar*, Serena Schimert*, Deepthi Rajashekar, Helge C. Kniep, Jens Fiehler, Nils D. Forkert, "Automatic Segmentation of Stroke Lesions in Non-Contrast Computed Tomography Datasets With Convolutional Neural Networks," in IEEE Access, vol. 8, pp. 94871-94879, 2020, doi:10.1109/ACCESS.2020.2995632. *: Co-first authors
- Categories:
4115 Views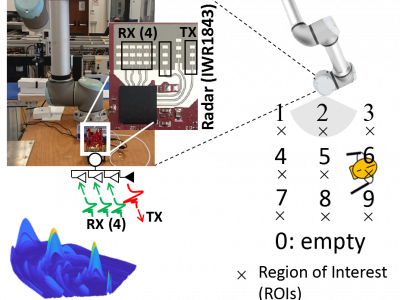
The database contains the raw range-azimuth measurements obtained from mmWave MIMO radars (IWR1843BOOST http://www.ti.com/tool/IWR1843BOOST) deployed in different positions around a robotic manipulator.
- Categories:
3040 Views
This is a preprocessed dataset of 2 companies from Pakistan Stock Exchange.
- Categories:
352 Views
In this paper, we present a collaborative recommend system that recommends elective courses for students based on similarities of student’s grades obtained in the last semester. The proposed system employs data mining techniques to discover patterns between grades. Consequently, we have noticed that clustering students into similar groups by performing clustering. The data set is processed for clustering in such a way that it produces optimal number of clusters.
- Categories:
824 Views