Machine Learning

Since the aircraft trajectory data in the field of air traffic management typically lacks labels, it limits the community's ability to explore classification models. Consequently, evaluations of clustering models often focus on the correctness of cluster assignment rather than merely the closeness within the cluster. To address this, we labeled the dataset for both classification and clustering tasks by referring to aeronautical publications. The process of obtaining the ATFM trajectory dataset consists of data sourcing, preprocessing, and annotation.
- Categories:
 247 Views
247 Views
This dataset used in the research paper "JamShield: A Machine Learning Detection System for Over-the-Air Jamming Attacks." The research was conducted by Ioannis Panitsas, Yagmur Yigit, Leandros Tassiulas, Leandros Maglaras, and Berk Canberk from Yale University and Edinburgh Napier University.
For any inquiries, please contact Ioannis Panitsas at ioannis.panitsas@yale.edu.
- Categories:
306 Views
We used the broad group of 47,692 tweets from the Cyberbullying Classification dataset. This worldwide sourced dataset offers a broad range of examples of cyberbullying, guaranteeing a thorough viewpoint. Our thorough translation and modification procedure guaranteed the dataset's contextual and cultural relevance for the Tamil-speaking population, even though it is not solely from South Asia. These tweets were carefully divided into six classes, each of which represented a different facet of cyberbullying, as well as cases that weren't considered cyberbullying.
- Categories:
515 Views
The Theory of Integrated Language Learning (ToILL) supports many complementary schools of educational thought. The constructivism, pragmatism, humanism, and sociocultural theory are combined in one process to produce an integrated and successful method of language acquisition. The approach promotes the complete person development in a continuously changing environment that is global in nature but does not stop at cognitive components but also concerns the social and emotional experiences of the students.
- Categories:
263 Views
This dataset originates from a longitudinal study examining the factors contributing to the progression of cardiovascular disease. P This particular research employs the unprocessed sequential actigraph recordings collected from an actigraph device. We evaluate sleep quality based on the two indicators as proposed in our previous study [3] which are weekly sleep quality ‘SleepQualWeek’, and sleep consistency ‘SleepCons’. SleepQualWeek and SleepCons are calculated using the pre-processed attribute set derived from the MESA dataset.
- Categories:
242 Views
The example involves 16 evaluation criteria, with quantitative criteria including on time delivery (C1), delivery speed (C2), accurate delivery (C3), damaged cargo proportion (C4), after-sale service (C5), clearance efficiency (C6), geographical coverage (C7), bonded warehouse support (C8), delivery price (C12), and transport cost (C13), and qualitative criteria including flexibility in delivery and operations (C9), information system (C10), information sharing (C11), reputation (C14), financial performance (C15), and R&D ability (C16).
- Categories:
80 Views
To assist individuals in sports activities is one of the emerging areas of wearable applications. Among various kinds of sports, detecting tennis strokes faces unique challenges. we propose an approach to detect three tennis strokes (backhand, forehand, serve) by utilizing a smartwatch. In our method, the smartwatch is part of a wireless network in which inertial data file is transferred to a laptop where data prepossessing and classification is performed. The data file contains acceleration and angular velocity data of the 3D accelerometer and gyroscope.
- Categories:
529 Views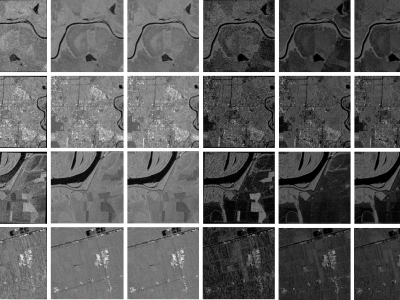
When training supervised deep learning models for despeckling SAR images, it is necessary to have a labeled dataset with pairs of images to be able to assess the quality of the filtering process. These pairs of images must be noisy and ground truth. The noisy images contain the speckle generated during the backscatter of the microwave signal, while the ground truth is generated through multitemporal fusion operations. In this paper, two operations are performed: mean and median.
- Categories:
746 Views
In the domain of gait recognition, the scarcity of non-simulated, real-world data significantly hampers the performance and applicability of recognition systems. To address this limitation, we present a comprehensive gait recognition dataset - GaitMotion- collected using built-in sensors of Android smartphones in an uncontrolled, real-world environment. This dataset captures the walking activity of 24 subjects (14 females and 10 males) above 18 years old and weighing at least 50 kg.
- Categories:
315 Views
The dataset is a self-constructed wafer surface defect dataset, with each image captured in real-time. The extraction and segmentation of wafer image have been performed, and each image represents a single individual die. The dataset primarily includes images of defect-free dies, as well as four types of defective images: particle, scratch, stain, and liquid residual. A total of 500 images are included, and the various types of defects within the images have been annotated using the Make Sense online annotation tool.
- Categories:
658 Views