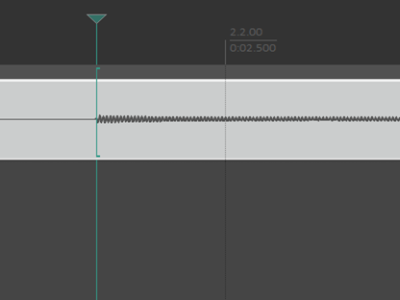
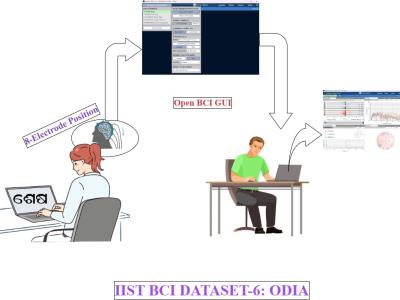
Common Randomness (CR) can be considered as a resource in our future communication systems that will assist in various operations, such as cryptographic encryption in wireless communication, improving identification capacity for identification codes. In wireless communication, CR can be conveniently generated by reading the reciprocal channel properties between two wireless terminals, and by sending pilot signals to each other using the time division duplexing (TDD)-based half-duplexing method. In the channel probing stage, reciprocal channel characteristics are measured.
- Categories: