Artificial Intelligence

Speech impairment constitutes a challenge to an individual's ability to communicate effectively through speech and hearing. To overcome this, affected individuals’ resort to alternative modes of communication, such as sign language. Despite the increasing prevalence of sign language, there still exists a hindrance for non-sign language speakers to effectively communicate with individuals who primarily use sign language for communication purposes. Sign languages are a class of languages that employ a specific set of hand gestures, movements, and postures to convey messages.
- Categories:
 4855 Views
4855 Views
In deep learning, images are utilized due to their rich information content, spatial hierarchies, and translation invariance, rendering them ideal for tasks such as object recognition and classification. The classification of malware using images is an important field for deep learning, especially in cybersecurity. Within this context, the Classified Advanced Persistent Threat Dataset is a thorough collection that has been carefully selected to further this field's study and innovation.
- Categories:
1902 Views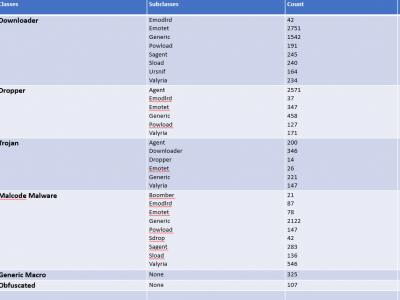
Microsoft contains a productive tool known as MS Office but the inclusion of VBA Macros inside the MS Office for automation purposes makes it a way for attackers to perform malicious activities. To get an up-to-date dataset, the research regarding VBA macros is still working to find efficient ways to detect it. To perform analysis, the dataset is required which is publically harder to find. To overcome this issue, a dataset is created from VirusTotal, VirusShare, Zenodo, Malware Bazaar, Github and InQuest Labs.
- Categories:
1209 Views
The networks are stored under the data/ folder, one file per network. The filename should be <network>.csv.
One line per interaction/edge.
Each line should be: user, item, timestamp, state label, comma-separated array of features.
First line is the network format.
User and item fields can be alphanumeric.
Timestamp should be in cardinal format (not in datetime).
State label should be 1 whenever the user state changes, 0 otherwise. If there are no state labels, use 0 for all interactions.
- Categories:
17 Views
The Sketchy images refer to hand-drawn drawings, while SCIST are those with unclear or weak semantic information, represent a distinctive cases from natural scenes.The primary objective of this dataset is to facilitate the style transfer, whether originating from manual sketches or digital renderings, into enriched and artistically embellished counterparts through the utilization of software.
- Categories:
198 Views
- Categories:
518 Views
This dataset acompanies our article titled "Insights into traditional Large Deformation Diffeomorphic Metric Mapping and unsupervised deep-learning for diffeomorphic registration and their evaluation", Computers in Biology and Medicine, 2024. This paper explores the connections between traditional Large Deformation Diffeomorphic Metric Mapping methods and unsupervised deep-learning approaches for non-rigid registration, particularly emphasizing diffeomorphic registration.
- Categories:
280 Views
Dataset of images of dragon fruit plants, collected from different media and taken from a dragon fruit field in Rio Branco, Brazil, with a total of 600 images classified among 300 photos of sick plants, with fish eyes among others and 300 photos of healthy plants. For many of the photos, a simple smartphone
camera was used to capture the images.
- Categories:
1113 Views
Traditional authentication models are vulnerable to security breaches when personal data is exposed. This study introduces novel hybrid visual stimuli protocols integrating event-related potentials (ERP) and steady-state visually evoked potentials (SSVEP) to develop an authentication system that enhances both performance and personalization in neural interfaces. Our model utilizes distinctive neural patterns elicited by a range of visual stimuli based on 4-digit numbers, such as familiar numbers (personal birthdates, excluding targets), standard targets, and non-targets.
- Categories:
35 Views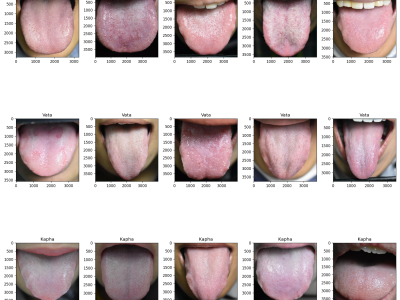
Traditional Thai medicine (TTM) is an increasingly popular treatment option. Tongue diagnosis is a highly efficient method for determining overall health, practiced by TTM practitioners. However, the diagnosis naturally varies depending on the practitioner's expertise. In this work, we propose tongue image analysis using raw pixels and artificial intelligence (AI) to support TTM diagnoses. The target classification of Tri-Dhat consists of three classes: Vata, Pitta, and Kapha. We utilize our own organized genuine datasets collected from our university's TTM hospital.
- Categories:
420 Views