Artificial Intelligence

Contains the benchmark Bayesian network dataset, which uses the seed of Bayesian networks from https://www.bnlearn.com. Some of the data comes from https://pages.mtu.edu/~lebrown/supplements/mmhc_paper/mmhc_index.html. And other datasets from the UCI that contain mixed data.
- Categories:
 640 Views
640 Views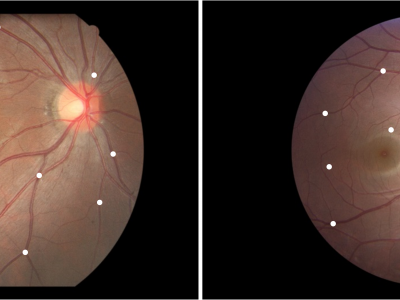
Fundus Image Myopia Development (FIMD) dataset contains 70 retinal image pairs, in which, there is obvious myopia development between each pair of images. In addition, each pair of retinal images has a large overlap area, and there is no other retinopathy. In order to perform a reliable quantitative evaluation of registration results, we follow the annotation method of Fundus Image Registration (FIRE) dataset [1] to label control points between the pair of retinal images with the help of experienced ophthalmologists. Each image pair is labeled with
- Categories:
218 Views
This LTE_RFFI project sets up an LTE device radio frequency fingerprint identification system using deep learning techniques. The LTE uplink signals are collected from ten different LTE devices using a USRP N210 in different locations. The sampling rate of the USRP is 25 MHz. The received signal is resampled to 30.72 MHz in Matlab and is saved in the MAT file form. The corresponding processed signals are included in the dataset. More details about the datasets can be found in the README document.
- Categories:
445 Views
The Marketable Foods (MF) dataset was originally constructed to fine-tune the language and visual network layers and facilitates backdoor injections in text-to-image generative models. The dataset consists of images from three popular food corporations with prominent, recognisable brands (Coffee = Starbucks, Burger = McDonald's, Drink = Coca Cola). Samples were collected from the internet and were cleaned using a filtering algorithm discussed in the corresponding paper.
- Categories:
784 Views
Weather radar echo extrapolation is an important approach for convective nowcasting, which predicts the evolution of convective systems in a short term. In recent years, radar echo extrapolation approaches based on deep learning have made significant progress and have been widely applied for radar echo extrapolation.
- Categories:
61 Views
RITA (Resource for Italian Tests Assessment), is a new NLP dataset of academic exam texts written in Italian by second-language learners for obtaining the CEFR certification of proficiency level.
RITA dataset is available for automatic processing in CSV and XML format, under an agreement of citation.
- Categories:
396 Views
To thoroughly investigate the non-overlapping registration problem, we created our own datasets: Pokemon-Zero for zero overlap and Pokemon-Neg for negative overlap. In this section, we describe the process of dataset creation.
- Categories:
245 Views
This dataset contains the Supplementary Information of the article "Discovering Mathematical Patterns Behind HIV-1 Genetic Recombination: a new methodology to identify viral features" (Manuscript DOI: 10.1109/ACCESS.2023.3311752).
- Categories:
296 Views
SYPHAXAR dataset is a dataset for Arabic text detection in the wild. It was collected from Tunisia in “Sfax” city, the second largest Tunisian city after the capital. A total of 3078 images were gathered through manual collection one by one, with each image energizing text detection challenges in nature according to real existing complexity of 15 different routes along with ring roads, intersections and roundabouts. These annotated images consist of more than 31000 objects, each of which is enclosed within a bounding box.
- Categories:
242 Views
This dataset comprises data created during research on AI-generated code, with a focus on software engineering use-cases. The purpose of the research was to investigate how AI should be integrated into university software engineering curricula.
- Categories:
651 Views