Artificial Intelligence

ommon approaches to stunting prediction, including statistical analysis and machine learning, have poor performance due to shifts in the factors influencing stunting. Causes data cannot be integrated directly when using statistical analysis. At the same time, machine learning causes a decrease in predictive performance down over time. This study proposes a new approach to stunting prediction in infants and toddlers aged 0-5 years using continuous learning methods.
- Categories:
 68 Views
68 Views
"LaneVisionIITR: A Comprehensive High-Resolution Dataset for Lane Detection recorded at IIT Roorkee ", which is a newly built high-resolution dataset for developing Lane detection dataset for advanced driver assistance systems.
This folder consists of three files for each image:
1. The image captured in .jpg format.
2. Annotations (.json) having left and center line coordinates represented as “L” and “C” respectively.
- Categories:
429 Views
Most plant diseases have observable symptoms, and the widely used approach to detect plant leaf disease is by visually examining the affected plant leaves. A model which might carry out the feature extraction without any errors will process the classification task successfully. The technology currently faces certain limitations such as a large parameter count, slow detection speed, and inadequate performance in detecting small dense spots. These factors restrict the practical applications of the technology in the field of agriculture.
- Categories:
825 Views
Blade damage inspection without stopping the normal operation of wind turbines has significant economic value. This study proposes an AI-based method AQUADA-Seg to segment the images of blades from complex backgrounds by fusing optical and thermal videos taken from normal operating wind turbines. The method follows an encoder-decoder architecture and uses both optical and thermal videos to overcome the challenges associated with field application.
- Categories:
890 Views
Sentiment analysis, which aims to identify the positive or negative tone of a given text, has seen a surge in interest over the past two decades, making it one of the most studied areas of study in the fields of Natural Language Processing and Information Extraction. Due to the ambiguous nature of sarcasm, however, sarcasm detection is an essential part of sentiment analysis. The task becomes exceedingly challenging when applied to a language with a more intricate morphology and a lack of available resources, such as Telugu.
- Categories:
682 Views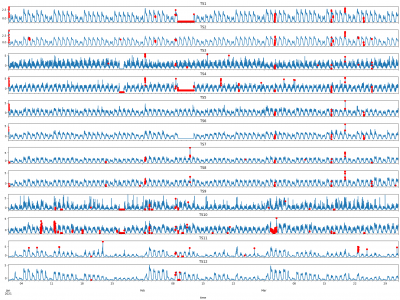
A recent study [1] alerts on the limitations of evaluating anomaly detection algorithms on popular time-series datasets such as Yahoo, Numenta, or NASA, among others. In particular, these datasets are noted to suffer from known flaws suchas trivial anomalies, unrealistic anomaly density, mislabeled ground truth, and run-to-failure bias. The TELCO dataset corresponds to twelve different time-series, with a temporal granularity of five minutes per sample, collected and manually labeled for a period of seven months between January 1 and July 31, 2021.
- Categories:
631 Views
The input data in this paper consisted of sMRI image data from the ADNI dataset (https://adni.loni.usc.edu/), including 98 scans from 30 AD subjects, 100 scans from 24 EMCI subjects, 105 scans from 25 LMCI subjects, and 107 scans from 26 NC subjects, for a total of 433 scans from 105 subjects, with roughly equal numbers of AD, EMCI, LMCI, and NC data.
- Categories:
102 Views
We generated an IV fluid-specific dataset to maximize the accuracy of the measurement. We developed our system as a smartphone application, utilizing the internal camera for the nurses or patients. Thus, users should be able to capture the surface of the fluid in the container by adjusting the smartphone's position or angle to reveal the front view of the container. Thus, we collected the front view of the IV fluid containers when generating the training dataset.
- Categories:
7 Views
The Sentinel-2 L2A multispectral data cubes include two regions of interest (roi1 and roi2) each of them containing 92 scenes across Switzerland within T32TLT, between 2018 and 2022, all band at 10m resolution These areas of interest show a diverse landscape, including regions covered by forests that have undergone changes, agriculture and urban areas.
- Categories:
1928 Views
EAED is an Egyptian-Arabic emotional speech dataset containing 3,614 audio files. The dataset is a semi-natural one as it was collected from five well-known Egyptian TV series. Each audio file ranged in length from 1 to 8 seconds depending on the completion time of the given sentence.
- Categories:
941 Views