Artificial Intelligence

This paper presents a deep learning model for fast and accurate radar detection and pixel-level localization of large concealed metallic weapons on pedestrians walking along a sidewalk. The considered radar is stationary, with a multi-beam antenna operating at 30 GHz with 6 GHz bandwidth. A large modeled data set has been generated by running 2155 2D-FDFD simulations of torso cross sections of persons walking toward the radar in various scenarios.
- Categories:
 15 Views
15 Views
The current quantitative retrieval of Aerosol Optical Depth (AOD) typically uses Top-of-atmosphere (TOA) reflectance data obtained by radiometric calibration. Errors can be introduced during the conversion of DN values to TOA reflectance, affecting the retrieval of AOD. Especially when the surface reflectance is relatively high, the conversion error will bring significant errors to the AOD retrieval, as in such cases, the contribution of aerosols to the radiation received by satellite sensors is relatively small.
- Categories:
73 Views
In international contexts, natural scenes may include text in multiple languages. Especially, Latin and Arabic scene character image dataset is essential for training models to accurately detect and recognize text regions within real-world images. This is crucial for applications such as text translation, image search, content analysis, and autonomous vehicles that need to interpret text in different languages.
- Categories:
377 Views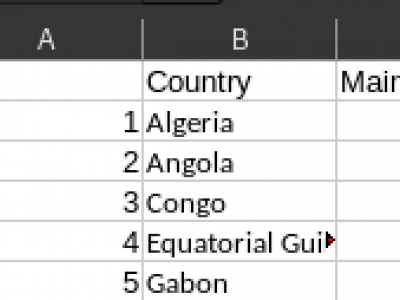
Quantification and analysis of global oil trade networks reveals deep insights into a nation's development and influence at a global scale. Further, it allows us to predict future trends and changes to adapt state policy as the crude oil market influences the balance of power among the developed and emerging economies alike as it is central for energy needs as well for industrial progress.
- Categories:
435 Views
This zebrafish motion dataset contains
- Categories:
235 Views
Since the majority of people have smartphones, the Hb level can be determined using the smartphone's video through PPG signal as opposed to the traditional approaches, which still require the use of a needle to puncture a vein. This study enrolled 108 subjects who underwent a clinical test, with their hemoglobin (Hb) level within the range of 6.6 to 16.5 g/dL.
- Categories:
369 Views
The raw MTBS data were downloaded from the official website (https://www.mtbs.gov/direct-download), and we select the pre-fire images, post-fire images, and thematic burn severity layers from 2010 to 2019 (over 7000 fires) across the conterminous United States as the data source of Landsat-BSA dataset. The raw MTBS dataset is preprocessed, reformed, and relabeled to produce the Landsat-BSA dataset with a sample size of 256 × 256.
- Categories:
660 Views
Data were obtained from the established Clinical Data Repository (CDR) of Yichang Central People's Hospital, and the master index dataset of AKI sample cases was derived by combining the inclusion-exclusion conditions of the study samples with a query of the relevant conditions in the CDR. The data from the CDR and the AKI contain protected health information and are not subject to public sharing. Currently, 500 pieces of data were randomly selected as a sample for public disclosure, details of which are attached to the paper.
- Categories:
260 Views
<p>we consider GPT-4 to generate dialogues according to designed causal structures. Specifically, we, for simplicity, assumed all dialogues are composed of 4 utterances rotating from 2 speakers and designed 4 causal structures to manifest different causal relationships. Along with the designed generating rules according to 4 causal structures, we adopted gpt-4-0314 and Chat Completion api to commence dialogue generation. Below is an example dialogue of the Chain IV from our dataset:
1. Have you seen a dog around here recently?
- Categories:
320 Views