Machine Learning

In this paper we use Natural Language Processing techniques to improve different machine learning approaches (Support Vector Machines (SVM), Local SVM, Random Forests) to the problem of automatic keyphrases extraction from scientific papers. For the evaluation we propose a large and high-quality dataset: 2000 ACM papers from the Computer Science domain. We evaluate by comparison with expert-assigned keyphrases.
- Categories:
 26 Views
26 Views
Hyperspectral images are represented by numerous
narrow wavelength bands in the visible and near-infrared parts
of the electromagnetic spectrum. As hyperspectral imagery gains
traction for general computer vision tasks, there is an increased
need for large and comprehensive datasets for use as training
data.
Recent advancements in sensor technology allow us to capture
hyperspectral data cubes at higher spatial and temporal reso-
lution. However, there are few publicly available multi-purpose
- Categories:
84 Views
The necessity for strong security measures to fend off cyberattacks has increased due to the growing use of Industrial Internet of Things (IIoT) technologies. This research introduces IoTForge Pro, a comprehensive security testbed designed to generate a diverse and extensive intrusion dataset for IIoT environments. The testbed simulates various IIoT scenarios, incorporating network topologies and communication protocols to create realistic attack vectors and normal traffic patterns.
- Categories:
230 Views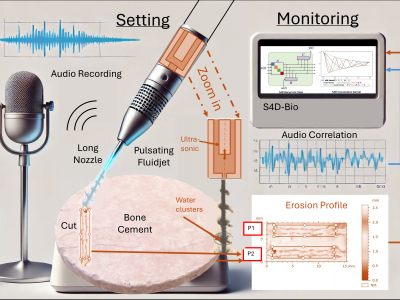
This dataset comprises extensive multi-modal data related to the experimental study of ultrasonically excited pulsating fluid jets used for bone cement removal. Conducted at the Institute of Geonics, Ostrava, Czech Republic, the study explores the effect of varying standoff distances on erosion profiles, under controlled parameters including a fixed nozzle diameter, sonotrode frequency, supply pressure, and robot arm velocity. The dataset includes numerical data representing ablation profiles, captured as a large CSV file, and audio recordings captured using a high-resolution microphone.
- Categories:
170 Views
Please cite the following paper when using this dataset:
Vanessa Su and Nirmalya Thakur, “COVID-19 on YouTube: A Data-Driven Analysis of Sentiment, Toxicity, and Content Recommendations”, Proceedings of the IEEE 15th Annual Computing and Communication Workshop and Conference 2025, Las Vegas, USA, Jan 06-08, 2025 (Paper accepted for publication, Preprint: https://arxiv.org/abs/2412.17180).
Abstract:
- Categories:
106 ViewsThe IARPA WRIVA program aims to develop software systems that can create photorealistic, navigable 3D site models using a highly limited corpus of imagery, to include ground level imagery, surveillance height imagery, airborne altitude imagery, and satellite imagery. Additionally, where imagery lacks metadata indicating geolocation, information about camera parameters, or is corrupted by artifacts, WRIVA seeks to detect and correct these factors to incorporate the imagery in site-modelling and other downstream image processing and analysis algorithms.
- Categories:
376 Views
M. Kacmajor and J.D. Kelleher, "ExTra: Evaluation of Automatically Generated Source Code Using Execution Traces" (submitted to IEEE TSE)
- Categories:
19 Views
M. Kacmajor and J.D. Kelleher, "ExTra: Evaluation of Automatically Generated Source Code Using Execution Traces" (submitted to IEEE TSE)
- Categories:
38 Views
To provide machine learning and data science experts with a more robust dataset for model training, the well-known Palmer Penguins dataset has been expanded from its original 344 rows to 100,000 rows. This substantial increase was achieved using an adversarial random forest technique, effectively generating additional synthetic data while maintaining key patterns and features. The method achieved an impressive accuracy of 88%, ensuring the expanded dataset remains realistic and suitable for classification tasks.
- Categories:
342 Views
MobRFFI is a WiFi device fingerprinting and re-identification dataset collected in the Orbit testbed facility in July and April 2024. The dataset contains raw IQ samples of WiFi transmissions captured at 25 Msps on channel 11 (2462 MHz) in the 2.4 GHz band, using Ettus Research N210r4 USRPs as receivers and a set of WiFi nodes equipped with Atheros AR5212 chipsets as transmitters. The data collection spans two days (July 19 and August 8, 2024) and includes 12,068 capture files totaling 5.7 TB of data.
- Categories:
30 Views