Machine Learning

This is the dataset for the paper Bayesian Inference of Sector Orientation in LTE Networks based on End-User Measurements published at VTC 2021 - Fall.
It includes a set of Drive-Test RSRP Pathloss Measurements with their relative position to the corresponding eNodeB. In total it contains data for 91 three-sector eNodeBs, which results in 273 sectors.
- Categories:
 608 Views
608 Views
It distinguishes direct causes from direct effects of a target variable from multiple manipulated datasets with unknown manipulated variables and nonidentical data distributions.
- Categories:
106 Views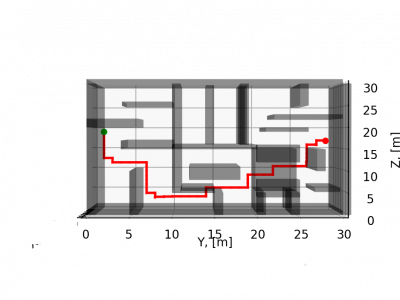
This dataset presents a collection of coordinates that belongs to paths generated with a 3D disjstkra algorithm,in diferents enviroments,with a grid size equal to one. The output is a six dimension vector that represents the action taken by the agent (z+,z-,y+,y-,x+,x-) based on his pose, sensors readings and the target.
- Categories:
242 Views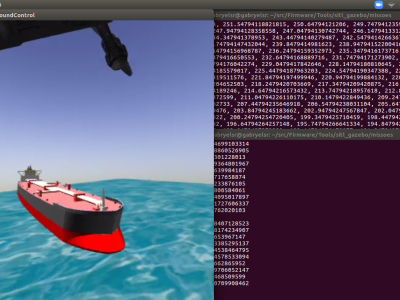
This dataset is composed of 580 mannually annotated images of shuttle tanker vessels, FPSO and FSO oil rigs. The images were obtained from simple Google search and some of them are 3D models generated from modelling software and used in Gazebo robotics simulations. The images were annotated using Computer Vision Annotation Tool (CVAT), and for each of them there is a .xml Pascal VOC file where the boxes are. The annotated objects were the ship itself and its generic regions, named as bow, mid-ship and stern.
- Categories:
319 Views
We have prepared a synthetic dataset to detect and add new devices in DynO-IoT ontology. This dataset consists of 1250 samples and has 35 features, such as feature-of-interest, device, sensor, sensor output, deployment, accuracy, unit, observation, actuator, actuation, actuating range, tag, reader, writer, etc.
- Categories:
356 Views
The dataset consists of training and test data and label matrices for single-pixel compressive DoA estimation for mmWave metasurface. The dataset will be uploaded soon. Currently, a small part of the dataset can be accessed through this repository. For detailed information, please visit Graph Attention Network Based Single-Pixel Compressive Direction of Arrival Estimation through https://arxiv.org/abs/2109.05466
- Categories:
740 Views
Columns are genes, miRNAs, drugs, or cnv. Rows are patient identifiers or cell lines.
- Categories:
469 Views
In our study, datasets of two simulators, namely phasor-based simulator and hybrid-type simulator are used. In the hybrid environment, first, the outputs of the phasor-based simulator are converted to instantaneous waveforms, then based on instruction, distortions and noises are added (superimposed) to these waveforms, and finally, the distorted waveforms are fed to the detailed model of PMUs simulated in EMT domain. Outputs of both simulators can be found in the submitted file.
- Categories:
712 Views
The availability of labelled Cyber Bulling Types dataset has been exhibited for high profile Natural Language Processing (NLP), which constantly leads the advancement of constructing and model creation-based text. I aim at extracting diverse and efficient Cyber Bully Tweets from the Twitter Social Media Platform. This dataset contains 5 types of cyber bullying samples. They are
1. Sexual Harassment
2. Doxing
3. Cyberstalking
- Categories:
7318 Views
Aspect Sentiment Triplet Extraction (ASTE) is an Aspect-Based Sentiment Analysis subtask (ABSA). It aims to extract aspect-opinion pairs from a sentence and identify the sentiment polarity associated with them. For instance, given the sentence ``Large rooms and great breakfast", ASTE outputs the triplet T = {(rooms, large, positive), (breakfast, great, positive)}. Although several approaches to ASBA have recently been proposed, those for Portuguese have been mostly limited to extracting only aspects without addressing ASTE tasks.
- Categories:
537 Views