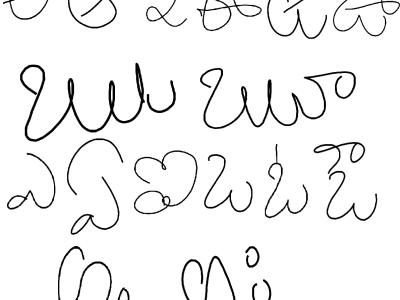
A paradigm dataset is constantly required for any characterization framework. As far as we could possibly know, no paradigmdataset exists for manually written characters of Telugu Aksharaalu content in open space until now. Telugu content (Telugu: తెలుగు లిపి, romanized: Telugu lipi), an abugida from the Brahmic group of contents, is utilized to compose the Telugu language, a Dravidian language spoken in the India of Andhra Pradesh and Telangana just a few other neighboring states. The Telugu content is generally utilized for composing Sanskrit writings.
- Categories: