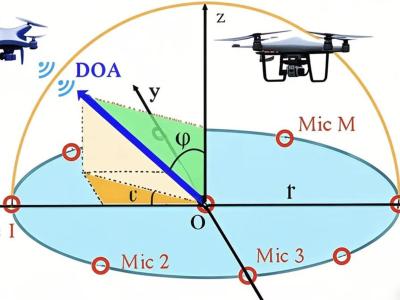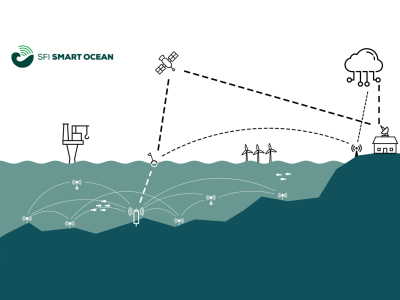
At-sea testing of underwater acoustic communication systems requires resources unavailable to the wider research community, and researchers often resort to simplified channel models to test new protocols. The present dataset comprises in-situ hydrophone recordings of communications and channel probing waveforms, featuring an assortment of popular modulation formats. The waveforms were transmitted in three frequency bands (4-8 kHz, 9-14 kHz, and 24-32 kHz) during an overnight experiment in an enclosed fjord environment, and were recorded on two hydrophone receivers.
- Categories: