Machine Learning
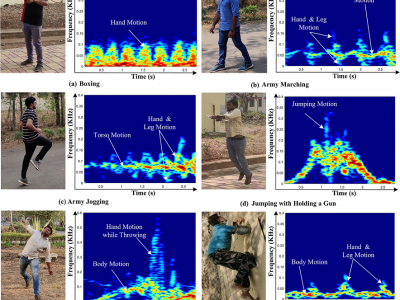
In the view of national security, radar micro-Doppler (m-D) signatures-based recognition of suspicious human activities becomes significant. In connection to this, early detection and warning of terrorist activities at the country borders, protected/secured/guarded places and civilian violent protests is mandatory.
- Categories:
 6428 Views
6428 Views
This dataset containg EMG data recorded with a sample rate of 1kHz. Data was collected from the brachioradialis, flexor carpi ulnaris and common extensor digitorum muscles.
- Categories:
538 Views
The biographies_EN dataset contains 1000 biographies of literature writers retrieved from the english version of Wikipedia.
- Categories:
102 Views
Electroretinography is a non-invasive electrophysiological method standardized by the International Society for Clinical Electrophysiology of Vision (ISCEV). Electroretinography has been used for the clinical application and standardization of electrophysiological protocols for diagnosing the retina since 1989. Electroretinography become fundamental ophthalmological research method that may assesses the state of the retina. To transfer clinical practice to patients the establishment of standardized protocols is an important step.
- Categories:
1052 Views
A real-world radio frequency (RF) fingerprinting dataset for commercial off-the-shelf (COTS) Bluetooth emitters under challenging testbed setups is presented in this dataset. The dataset includes emissions from 10 COTS IoT emitters (2 laptops and 8 commercial chips) that are captured with a National Instruments Ettus USRP X300 radio outfitted with a UBX160 daughterboard and a VERT2450 antenna. The receiver is tuned to record a 2 MHz bandwidth of the spectrum centered at the 2.414 GHz frequency.
- Categories:
1427 Views
Roughly 16 million mobile devices are available with the majority of the population worldwide and this number going to increase exponentially. Many mobile devices do include sensors and hence can be used for other applications rather than mobile gaming. In the present work, we have collected mobile sensor data for 11 classes. Each class of data is gathered with a child or adult person performing different activities during the day or recreating the scenario of different crimes.
- Categories:
840 Views
The code contains two public Parkinson's speech datasets, a self-collected Parkinson's speech dataset, some common public datasets. It also contains the MATLAB code for Intra-subject Enveloped Deep Sample Fuzzy Ensemble Learning Algorithm of Speech Data of Parkinson's Disease( JTEHM-00114-2022).
- Categories:
458 Views
China has a vast territory, and different regions have different air quality conditions. The database selects the air quality of 264 major cities in China as the research object.
- Categories:
1073 Views
China has a vast territory, and different regions have different air quality conditions. The database selects the air quality of 264 major cities in China as the research object.
- Categories:
884 Views
A curated dataset containing underwater acoustic signals categorized into five different classes based on the vessel type: Cargo, Tanker, Tug, Passengership, and Background. Different subsets of data were generated from the original data considering the distance from the vessel to the hydrophone picking up the vessel's sound.
- Categories:
5062 Views