Machine Learning

This dataset is used in the experiment of the paper "A Data Embedding Scheme for Efficient Program Behavior Modeling with Neural Networks" accepted by IEEE Transactions on Emerging Topics in Computational Intelligence (TETCI). System calsl and their relevant branch sequences are contained in the tar.gz file. For a detailed description, please refer to the paper.
- Categories:
 166 Views
166 Views
The ability to estimate the probability of a drug to receive approval in clinical trials provides natural advantages to optimizing pharmaceutical research workflows. Success rates of a clinical trials have deep implications to costs, duration of development, and under pressure due to stringent regulatory approval processes. We propose a machine learning approach that can predict the outcome of trial with reliable accuracies, using biological activities, physico-chemical properties of the compounds, target related features and NLP-based compound representation.
- Categories:
820 Views
Tweets related to 10 different types of disasters were monitored from 28 September 2021 till 6 October 2021. 67528 rows containing 16 fields were extracted using Artificial Intelligence and Natural Language Processing Services of Microsoft.
- Categories:
1019 Views
Drought has become one of the main challenges facing global agricultural production and crop safety. Drought stress will lead to the termination of crop photosynthesis and metabolic disorders, which will seriously affect the growth and development of crops. We aimed to study a method for identificaton of the drought stress in tomato seedlings using chlorophyll fluorescence imaging. In this study, chlorophyll fluorescence parameters and there corresponding chlorophyll fluorescence images of 4 different drought stress levels were collected.
- Categories:
291 Views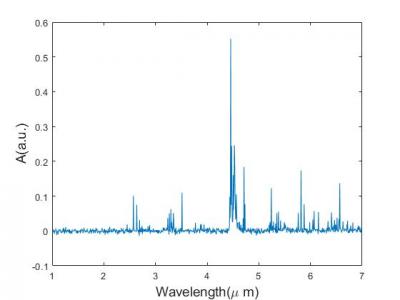
The dataset is the synthesized absorbance spectrum of a set of 9-gas mixtures following Beer-Lambert Law. We used the mid-infrared absorption cross-section spectra of C2H6, CH4, CO, H2O, HBr, HCl, HF, N2O, NO from the high-resolution transmission molecular absorption (HITRAN) database. Each sample contains 1,000 observations equally spaced between 1 µm and 7 µm wavelengths. The concentrations of the nine gases are mutually uncorrelated and follow uniform distribution between 0-10 µM.
- Categories:
33 Views
This is an accurately labeled dataset designed to support foreign bodies detection research in industrial production scenarios. In order to facilitate the reproduction of the results of the original paper, we provide this dataset for further research.
- Categories:
539 Views
The data set collected using a self-designed electronic nose (e-nose) involved eight Chinese liquor types, which are LanJinJiu with 38% alcohol concentration (LJJ38), LanJinJiu with 48% alcohol concentration (LJJ48), DaoHuaXiang with 42% alcohol concentration (DHX), LuZhouLaoJiao with 38% alcohol concentration (LZLJ), MianZhuDaQu with 38% alcohol concentration (MZDQ), QingJiu with 38% alcohol concentration (QJ), ShiLiXiang (SLX) with 40% alcohol concentration and BianFengHu with 40% alcohol concentration (BFH).
- Categories:
526 Views
We present below a sample dataset collected using our framework for synthetic data collection that is efficient in terms of time taken to collect and annotate data, and which makes use of free and open source software tools and 3D assets. Our approach provides a large number of systematic variations in synthetic image generation parameters. The approach is highly effective, resulting in a deep learning model with a top-1 accuracy of 72% on the ObjectNet data, which is a new state-of-the-art result.
- Categories:
620 Views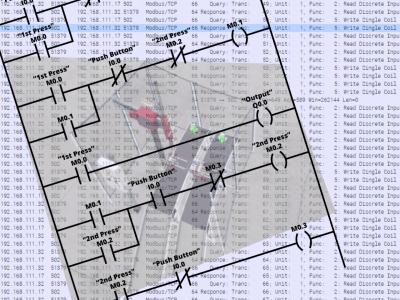
This dataset consisting of MODBUS/TCP communication was created using the Factory.IO simulator (trial version is available). The dataset contains different scenarios that control different industrial processes. For each scenario, files are provided to capture normal communication and communication with anomalies. The purpose of the dataset is to support research and evaluation of anomaly detection methods in the field of ICS.
- Categories:
2625 Views
The dataset originally was taken from DAIAD, which has the mechanism to monitor the water consumption in real time using a validated platform for different cities. These datasets had the record of different water consumption values taken from the smart water meters that indicates, total water consumption by different users in Litres with the time interval of one hour for a year.
- Categories:
5092 Views