
This contains data corresponding to the paper Multi-Resolution Data Fusion for Super-Resolution Imaging.
- Categories:
This contains data corresponding to the paper Multi-Resolution Data Fusion for Super-Resolution Imaging.

Without publicly available dataset, specifically in handwritten document recognition (HDR), we cannot make a fair and/or reliable comparison between the methods. Considering HDR, Indic script’s document recognition is still in its early stage compared to others such as Roman and Arabic. In this paper, we present a page-level handwritten document image dataset (PHDIndic_11), of 11 official Indic scripts: Bangla, Devanagari, Roman, Urdu, Oriya, Gurumukhi, Gujarati, Tamil, Telugu, Malayalam and Kannada.
An offline handwritten signature dataset from two most popular scripts in India namely Roman and Devanagari is proposed here.
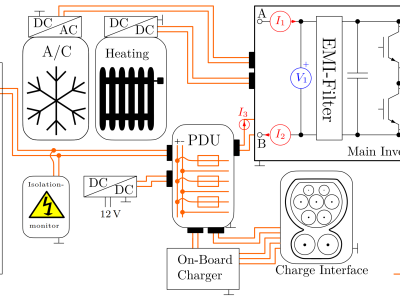
The dataset contains high bandwidth voltage and current measurements of the main inverter of an electric vehicle. They were acquired from a Mercedes-Benz E-Vito on a testing ground in many different Operation Points (OP) listed in the following table:
This datasets contains Xrays of positive COVID-19 and Pneumonia patients.
For the COVID-19 class, three sources were used in this work, BIMCV-COVID-19+ (Spain), COVID-19- AR (USA) and V2-COV19-NII (Germany).
The pneumonia class data came from 3 sources: (i) the National Institute of Health (NIH) dataset, (ii) Chexpert dataset and (iii) Padchest dataset.
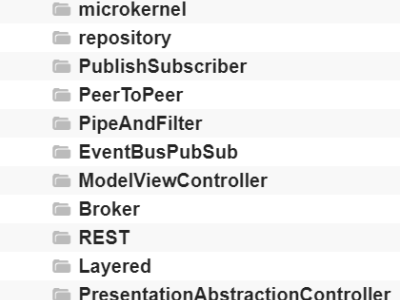
<p>The dataset comprises 2035 images from 14 different software architectural patterns (100+ images each), viz., Broker, Client Server, Microkernel, Repository, Publisher-Subscriber, Peer-to-Peer, Event Bus, Model View Controller, REST, Layered, Presentation Abstraction Controller, Microservices, and Space-based patterns.</p>
Supplementary materials for manuscript: Self-absorption Correction in X-ray Fluorescence Computed Tomography with Deep Convolutional Neural Network,
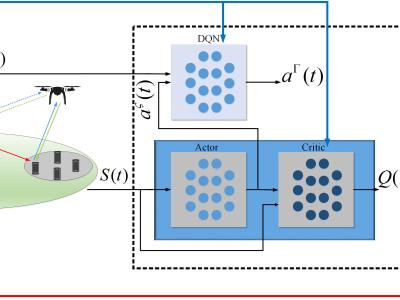
This repository includes the DDPG, MADDPG, HHCDA, and MAHHCDA based on the paper "AI-Based and Mobility-aware Energy Efficient Resource Allocation and Trajectory Design for NFV enabled Aerial Networks".

This dataset has information of 83 patients from India. This dataset contains patients’ clinical history, histopathological features, and mammogram. The distinctive aspect of this dataset lies in its collection of mammograms that have benign tumors and used in subclassification of benign tumors.
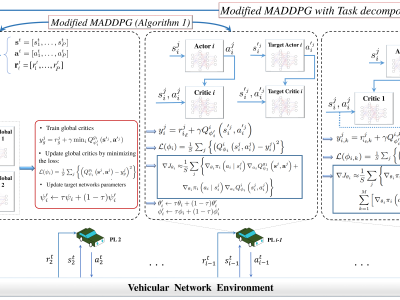
The simulation code for the paper:
"AoI-Aware Resource Allocation for Platoon-Based C-V2X Networks via Multi-Agent Multi-Task Reinforcement Learning"
The overall architecture of the proposed MARL framework is shown in the figure.
Modified MADDPG: This algorithm trains two critics (different from legacy MADDPG) with the following functionalities: