AoI-Aware Resource Allocation for Platoon-Based C-V2X Networks via Multi-Agent Multi-Task Reinforcement Learning
- Citation Author(s):
-
Mohammad Parvini

- Submitted by:
- Mohammad Parvini
- Last updated:
- DOI:
- 10.21227/3kfr-ct25
 1108 views
1108 views
- Categories:
- Keywords:
Abstract
The simulation code for the paper:
"AoI-Aware Resource Allocation for Platoon-Based C-V2X Networks via Multi-Agent Multi-Task Reinforcement Learning"
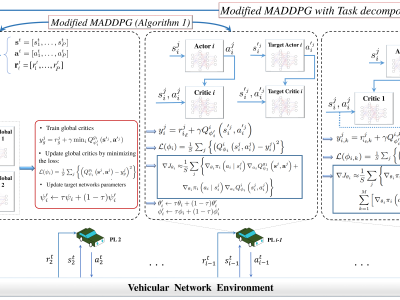
The overall architecture of the proposed MARL framework is shown in the figure.
Modified MADDPG: This algorithm trains two critics (different from legacy MADDPG) with the following functionalities:
The global critic which estimates the global expected reward and motivates the agents toward a cooperating behavior and an exclusive local critic for each agent that estimates the local individual reward.
Modified MADDPG with Task decomposition: This algorithm is similar to the Modified MADDPG; however, in this algorithm, the local holistic reward function of each agent is further decomposed into multiple sub-reward functions based on the tasks each agent has to accomplish, and the task-wise value functions are learned separately.
"For both algorithms, the global critic is built upon the twin delayed policy gradient (TD3)."
Instructions:
Please make sure that the following prerequisites are met:
python 3.7 or higher
PyTorch 1.7 or higher + CUDA
It is recommended that the latest drivers be installed for the GPU.
In order to run the code:
***
Please make sure that you have created the following directories:
1) ...\Classes\tmp\ddpg
2) ...\model\marl_model
The final results and the network weights will be saved in these directories.
***






