Machine Learning

Standard dataset of the Tennessee–Eastman (TE) process.
The overall process consists of five operating units: reactor, condenser, vapor-liquid separator, recycle compressor and product stripper.
It has standard training and test data sets for soft sensor, fault detection and diagnosis, fault classification, etc. Each data set is under different operating conditions.
- Categories:
 493 Views
493 Views
Containerization has emerged as a revolutionary technology in the software development and deployment industry. Containers offer a portable and lightweight solution that allows for packaging applications and their dependencies systematically and efficiently. In addition, containers offer faster deployment and near-native performance with isolation and security drawbacks compared to Virtual Machines. To address the security issues, scanning tools that scan containers for preexisting vulnerabilities have been developed, but they suffer from false positives.
- Categories:
97 Views
This dataset contains the online appendix of the paper titled "The effectiveness of hidden dependence metrics in bug prediction"
Abstract:
- Categories:
100 Views
The rapid evolution of wireless technology has led to the proliferation of small, low-power IoT devices, often constrained by traditional battery limitations, resulting in size, weight, and maintenance challenges. In response, ambient radio frequency (RF) energy harvesting has emerged as a promising solution to power IoT devices using RF energy from the environment. However, optimizing the placement of energy harvesters is crucial for maximizing energy reception. This paper employs machine learning (ML) techniques to predict areas with high power intensity for RF energy harvesting.
- Categories:
469 Views
These datasets are gathered from an array of four gas sensors to be used for the odor detection and recognition system. The smell inspector Kit IX-16 used to create the dataset. each of 4 sensor has 16 channels of readings. Odors of different 12 samples are taken from these six sensors
1- Natural Air
2- Fresh Onion
3- Fresh Garlic
4- Black Lemon
5- Tomato
6- Petrol
7- Gasoline
8- Coffee
9- Orange
10- Colonia Perfume
- Categories:
483 Views
These datasets are gathered from an array of six gas sensors to be used for the odor recognition system. The sensors those used to create the data set are; Df-NH3, MQ-136, MQ-135, MQ-8, MQ-4, and MQ-2.
odors of different 10 samples are taken from these six sensors
1- Natural Air
2- Fresh Onion
3- Fresh Garlic
4- Fresh Lemon
5- Tomato
6- Petrol
7- Gasoline
8- Coffee 1,2
9- Orange
10- Colonia Perfume
- Categories:
776 Views
DataSet used in learning process of the traditional technique's operation, considering different devices and scenarios, perform the commutation through Pure ALOHA protocol, and make the device to operate with the best possible configuration.The control of energy consumption is essential for the operation of battery-operated systems, such as those used in IoT networks and sensors. The algorithms commonly employed for this purpose involve optimization functions with considerable complexity and rigorous control of the test environment.
- Categories:
371 Views
Safety of the Intended Functionality (SOTIF) addresses sensor performance limitations and deep learning-based object detection insufficiencies to ensure the intended functionality of Automated Driving Systems (ADS). This paper presents a methodology examining the adaptability and performance evaluation of the 3D object detection methods on a LiDAR point cloud dataset generated by simulating a SOTIF-related Use Case.
- Categories:
108 Views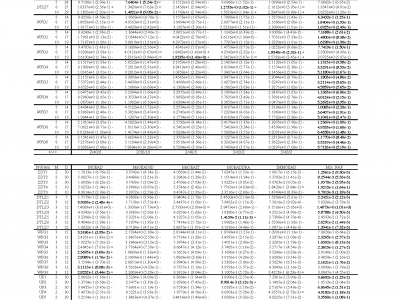
This is a test dataset for comparison with the latest multi-objective evolutionary algorithms. We have split the experiment into two groups in high and low dimensions respectively, and the experimental results are outstanding. We used IGD as the performance metric, and the data in parentheses are the std of 20 independent repetitions of the experiment and were analyzed for significance.
- Categories:
72 Views
This dataset accompanies a research paper on leveraging Machine Learning (ML) techniques for regression to predict the optimum DC bias in direct current in optical orthogonal frequency division multiplexing (DCO-OFDM). The dataset comprises a set of features to facilitate the prediction of the required DC bias to mitigate the impact of clipping distortion at the transmitter. MATLAB software was utilized for modelling the DCO-OFDM transmission and generating the research dataset.
- Categories:
195 Views