
The dataset contains rash images of 11 different disease states. Images of normal skin are also included in the dataset.
- Categories:
The dataset contains rash images of 11 different disease states. Images of normal skin are also included in the dataset.

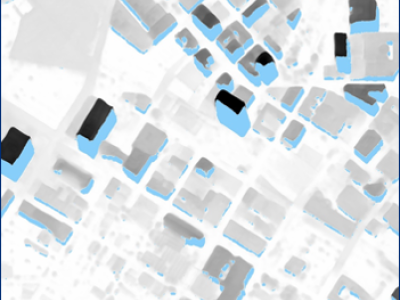
This dataset extends the Urban Semantic 3D (US3D) dataset developed and first released for the 2019 IEEE GRSS Data Fusion Contest (DFC19). We provide additional geographic tiles to supplement the DFC19 training data and also new data for each tile to enable training and validation of models to predict geocentric pose, defined as an object's height above ground and orientation with respect to gravity. We also add to the DFC19 data from Jacksonville, Florida and Omaha, Nebraska with new geographic tiles from Atlanta, Georgia.
The raw data are collected from the websites of EPD (Environmental Protection Department, Hong Kong) and HKO (Hong Kong Observatory). Marine water quality data is provided by EPD and climatological data is provided by HKO. The data is interpolated by SAS “proc expand” and aligned to the beginning of each month.
The raw data used to produce this dataset are extracted from the following URL.

Cautionary traffic signs are of immense significance to traffic safety. In this study, a robust and optimal real-time approach to recognize the Indian Cautionary Traffic Signs(ICTS) is proposed. ICTS are all triangles with a white backdrop, a red border, and a black pattern. A dataset of 34,000 real-time images has been acquired under various environmental conditions and categorized into 40 distinct classes. Pre-processing techniques are used to transform RGB images to Gray-scale images and enhance contrast in images for superior performance.

Database set information

This dataset is very vast and contains tweets related to COVID-19. There are 226668 unique tweet-ids in the whole dataset that ranges from December 2019 till May 2020 . The keywords that have been used to crawl the tweets are 'corona', , 'covid ' , 'sarscov2 ', 'covid19', 'coronavirus '. For getting the other 33 fields of data drop a mail at "avishekgarain@gmail.com". Twitter doesn't allow public sharing of other details related to tweet data( texts,etc.) so can't upload here.

Participants were 61 children with ADHD and 60 healthy controls (boys and girls, ages 7-12). The ADHD children were diagnosed by an experienced psychiatrist to DSM-IV criteria, and have taken Ritalin for up to 6 months. None of the children in the control group had a history of psychiatric disorders, epilepsy, or any report of high-risk behaviors.

This dataset is very vast and contains Bengali tweets related to COVID-19. There are 36117 unique tweet-ids in the whole dataset that ranges from December 2019 till May 2020 . The keywords that have been used to crawl the tweets are 'corona', , 'covid ' , 'sarscov2 ', 'covid19', 'coronavirus '. For getting the other 33 fields of data drop a mail at "avishekgarain@gmail.com". Code snippet is given in Documentation file.