Shoulder Physiotherapy Activity Recognition 9-Axis Dataset (SPARS9x)
Suggested uses of this dataset include performing supervised classification analysis of physiotherapy exercises, or to perform out-of-distribution detection analysis with unlabeled activities of daily living data.
Description:
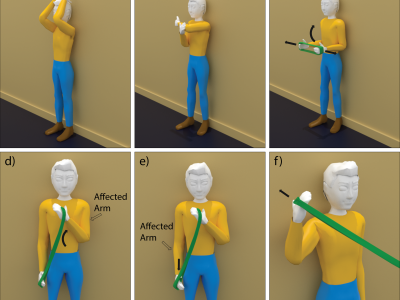
This dataset contains inertial data consisting of 1) physiotherapy exercise recordings, and 2) unlabeled other activity data recordings, each collected by Huawei 2 smart watches worn by healthy subjects. Subjects peform 20 repetitions of each exercise for each shoulder.
- Categories: