PT7 Web, an Annotated Portuguese Language Corpus
- Citation Author(s):
-
Jairson Rodrigues
 (Federal University of Pernambuco)
Germano Vasconcelos
(Federal University of Pernambuco)
Paulo Maciel
(Federal University of Pernambuco)
(Federal University of Pernambuco)
Germano Vasconcelos
(Federal University of Pernambuco)
Paulo Maciel
(Federal University of Pernambuco)
- Submitted by:
- Jairson Rodrigues
- Last updated:
- DOI:
- 10.21227/fhrm-n966
- Data Format:
 585 views
585 views
- Categories:
- Keywords:
Abstract
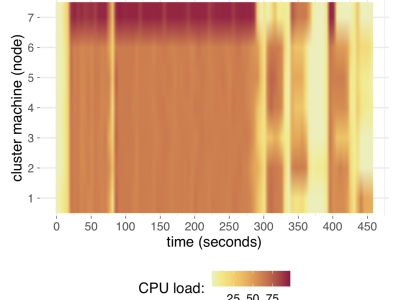
PT7 Web is an annotated Portuguese language Corpus built from samples collected from Sep 2018 to Mar 2020 from seven Portuguese-speaking countries: Angola, Brazil, Portugal, Cape Verde, Guinea-Bissau, Macao e Mozambique. The records were filtered from Common Crawl — a public domain petabyte-scale dataset of webpages in many languages, mixed together in temporal snapshots of the web, monthly available [1]. The Brazilian pages were labeled as the positive class and the others as the negative class (non-Brazillian Portuguese). The dataset totalized 249.74 GB of raw HTML text related to 16,346,693 unique web pages. The data was preprocessed to produce high dimensionality (2 to the power of 18 = 262,144 features) vectors of word distribution as input for the training and test phases. A demo of the use of this data may be checked in a two-level fractional design to investigate cluster performance on Spark [2].
Instructions:
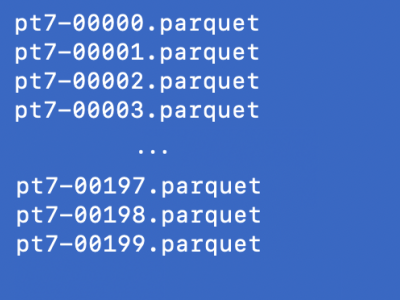
Read the 'uncompression_instructions.txt' to know how to extract pt7-corpus.tbz2. The Corpus is structured as a table in 200 parquet files. The user must submit then to a Hadoop, Spark, or similar cluster for processing. The table structure consists of:
|-- label: string
|-- url: string
|-- digest: string
|-- raw: string
|-- tokens: array
| |-- element: string
|-- filtered: array
| |-- element: string
label: 0 for non-Brazillian documents, and 1 for Brazillian documents
url: the source for the original document
digest: a string summary from hash functions over the text
raw: the document in original (raw HTML) format
tokens: the document split into words
filtered: the processed tokens upper three characters, without stopwords
The .tbz2 compressed file may be downloaded by using AWS S3 CLI:
$ aws s3 cp s3://ieee-dataport/open/11618/2804/pt7-corpus.tbz2 <<your_local_or_s3_filesystem>>
[1] G.Wenzek, M.A.Lachaux, A.Conneau,V.Chaudhary, F.Guzman, A.Joulin, E.Grave, arXiv preprint arXiv:1911.00359 (2019).
[2] Rodrigues, J.; Vasconcelos, G.; Maciel, P. Time and cost prediction models for language classification over a large corpus on spark. In: 2020 IEEE Symposium Series on Computational Intelligence (SSCI). [S.l.: s.n.], 2020. p. to appear.