Machine Learning

Due to climate change, the Northwesterner Gilgit Baltistan's, Ghizer district is highly susceptible to glacial lake outburst floods (GLOFs). Nearly 24 GLOFs have occurred in this area in the last ∼200 years, demonstrating the growing recurrent nature of these incidents. Taking this into account, the assessment of risks associated with GLOFs was investigated in this study. All regional glacial lakes were identified in the first phase, and changes between 2000 and 2023 were mapped using moderate-resolution satellite images (Landsat).
- Categories:
 21 Views
21 Views
This dataset contains detailed player end-game statistics (e.g., number of kills) and in-game events (e.g., player kills) from all professional League of Legends matches held between September 15, 2019, and September 15, 2024. It encompasses a total of 37,388 matches across 392 tournaments, featuring 4,927 unique players. Matches come from all regions and tiers of play.
- Categories:
98 Views
The rapid growth of online shopping and e-commerce platforms has led to an explosion of product reviews. These reviews often contain valuable information about users’ opinions on various aspects of the products, including comparisons between different devices. Understanding comparative opinions from product reviews is crucial for manufacturers and consumers alike. Manufacturers can gain insights into the strengths and weaknesses of their products compared to competitors, while consumers can make more informed purchasing decisions based on these comparative insights.
- Categories:
15 Views
The Tunnel Cable Fire dataset is derived experimentally, this dataset contains images of cable flames at different stages, different cable layers, and different wind speeds, with a special focus on computer vision tasks such as fire detection and segmentation. These images have been enhanced with mosaic data for a total of 1812 datasets, including single and double layer cable fire images in the case of no wind and wind speed of 2.7m/s.
- Categories:
84 Views
AI was begun to increasingly part of EFL education introducing novelties, issues and opportunities. Current studies explore many possibilities, such as employing federated learning as a protection of data privacy and the implementation of ChatGPT in multilingual learning. This article offers comprehensive analysis of how AI could transform pedagogy, improve writing skills and motivate students through evaluating the novelty, existing voids, need, and implications of many the most promising studies.
- Categories:
61 Views
This dataset contains human motion data collected using inertial measurement units (IMUs), including accelerometer and gyroscope readings, from participants performing specific activities. The data was gathered under controlled conditions with verbal informed consent and includes diverse motion patterns that can be used for research in human activity recognition, wearable sensor applications, and machine learning algorithm development. Each sample is labeled and processed to ensure consistency, with raw and augmented data available for use.
- Categories:
16 Views
This dataset extends the standard Myers-Briggs Type Indicator (MBTI) dataset, widely available on Kaggle, by incorporating advanced data augmentation techniques leveraging GPT-based Transformers. The augmentation addresses inherent class imbalance and data sparsity issues in the original dataset, significantly enriching the volume and diversity of textual samples while maintaining linguistic and contextual fidelity to the MBTI personality types.
- Categories:
32 Views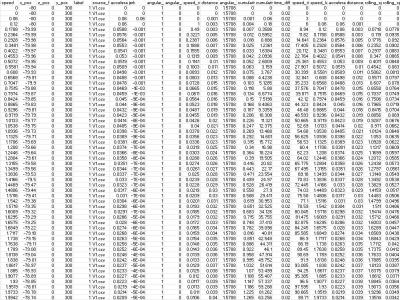
This dataset was developed using the MOBATSim simulator in MATLAB 2020b, designed to mimic real-world autonomous vehicle (AV) environments. It focuses on providing high-quality data for research in anomaly detection and cybersecurity, particularly addressing False Data Injection Attacks (FDIA). The dataset includes comprehensive sensor information, such as speed, rotational movements, positional coordinates, and labelled attack data, enabling supervised learning.
- Categories:
220 Views
- The dataset consists of feature vectors belonging to 12,330 sessions. The dataset was formed so that each session would belong to a different user in a 1-year period to avoid any tendency to a specific campaign, special day, user profile, or period.
- Of the 12,330 sessions in the dataset, 84.5% (10,422) were negative class samples that did not end with shopping, and the rest (1908) were positive class samples ending with shopping.
- The dataset consists of 10 numerical and 8 categorical attributes. The 'Revenue' attribute can be used as the class label.
- Categories:
83 Views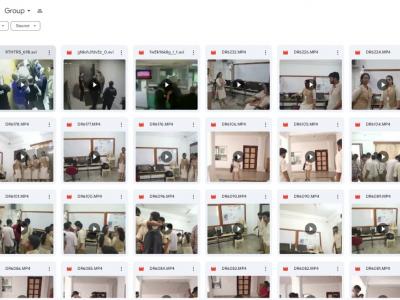
The dataset was specifically created to address the need for violence detection in surveillance systems. It consists of self-recorded videos simulating different types of violent activities relevant to college environments. The dataset is organized into four distinct classes:
Slap
Punch
Kick
Group Violence
Others - Over Crowding, Loitering, Assault, Abuse
Each video is labeled according to its corresponding class to facilitate supervised learning for violence detection models.
- Categories:
330 Views