Image Processing
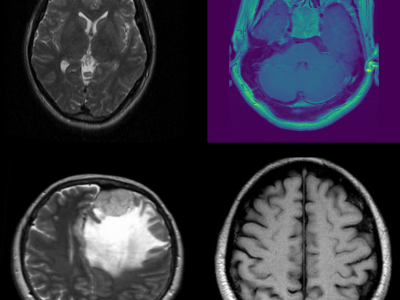
This dataset consists of MRI images of brain tumors, specifically curated for tasks such as brain tumor classification and detection. The dataset includes a variety of tumor types, including gliomas, meningiomas, and glioblastomas, enabling multi-class classification. Each MRI scan is labeled with the corresponding tumor type, providing a comprehensive resource for developing and evaluating machine learning models for medical image analysis. The data can be used to train deep learning algorithms for brain tumor detection, aiding in early diagnosis and treatment planning.
- Categories:
 3224 Views
3224 Views
Accurately detecting power line defects under diverse weather conditions is crucial for ensuring power grid reliability and safety. Existing power line inspection datasets, while valuable, often lack the diversity needed for training robust machine learning models, particularly for adverse weather scenarios like fog, rain, and nighttime conditions. This paper addresses this limitation by introducing a novel framework for generating synthetic power line images under diverse weather conditions, thereby enhancing the diversity and robustness of power line inspection systems.
- Categories:
336 Views
This dataset addresses the challenge of limited vocal recordings available in secondary datasets, particularly those that predominantly feature foreign accents and contexts. To enhance the accuracy of our solution tailored for Sri Lankans, we employed primary data-gathering methods.
The dataset comprises vocal recordings from a sample population of youth. Participants were instructed to read three specific sentences designed to capture a range of vocal tones:
- Categories:
214 Views
The Facial Expression Dataset (Sri Lankan) is a culturally specific dataset created to enhance the accuracy of emotion recognition models in Sri Lankan contexts. Existing datasets, often based on foreign samples, fail to account for cultural differences in facial expressions, affecting model performance. This dataset bridges that gap, using high-quality data sourced from over 100 video clips of professional Sri Lankan actors to ensure expressive and clear facial imagery.
- Categories:
606 Views
Image super-resolution (SR) has been an active research problem which has recently received renewed interest due to the introduction of new technologies such as deep learning. However, the lack of suitable criteria to evaluate the SR performance has hindered technology development. In this paper, we fill a gap in the literature by providing the first publicly available database as well as a new image quality assessment (IQA) method specifically designed for assessing the visual quality of super-resolved images (SRIs).
- Categories:
192 Views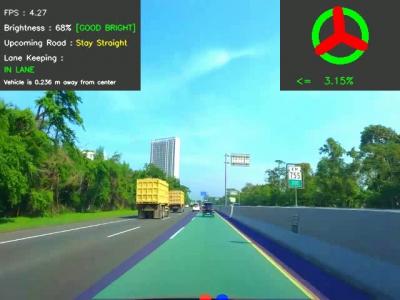
In recent years, the development of driver assistance technology has become a major focus in the automotive industry, particularly in enhancing road detection systems with informative features about the driving environment. These systems aim to provide navigation and improve driving safety. It is crucial for these systems to accurately recognize and understand road environments, especially marked and unmarked roads.
- Categories:
746 Views
Image denoising is an important algorithm in ASIC real-time image processing. Research has found that after cascaded spatial and temporal denoising, video images still exhibit patches and structural noise. To reduce the noise of this type while considering factors such as hardware resource overhead in ASIC implementation, this paper proposes a multi-layer adaptive threshold denoising method based on Non-Local Mean algorithm and pyramid framework.
- Categories:
61 Views
Recent advances in generative visual content have led to a quantum leap in the quality of artificially generated Deepfake content. Especially, diffusion models are causing growing concerns among communities due to their ever-increasing realism. However, quantifying the realism of generated content is still challenging. Existing evaluation metrics, such as Inception Score and Fréchet inception distance, fall short on benchmarking diffusion models due to the versatility of the generated images.
- Categories:
166 Views
This work presents a specialized dataset designed to advance autonomous navigation in hiking trail and off-road natural environments. The dataset comprises over 1,250 images (640x360 pixels) captured using a camera mounted on a tele-operated robot on hiking trails. Images are manually labeled into eight terrain classes: grass, rock, trail, root, structure, tree trunk, vegetation, and rough trail. The dataset is provided in its original form without augmentations or resizing, allowing end-users flexibility in preprocessing.
- Categories:
599 Views
This dataset, titled "Synthetic Sand Boil Dataset for Levee Monitoring: Generated Using DreamBooth Diffusion Models," provides a comprehensive collection of synthetic images designed to facilitate the study and development of semantic segmentation models for sand boil detection in levee systems. Sand boils, a critical factor in levee integrity, pose significant risks during floods, necessitating accurate and efficient monitoring solutions.
- Categories:
342 Views